MiniMind 轻量大模型的训练与微调
原项目地址:https://github.com/jingyaogong/minimind?tab=readme-ov-file
整体概述
MiniMind模型架构:
基于 Transformer 的 Decoder-Only 结构,采用 RMSNorm 进行每个子层输入的归一化处理。
使用旋转位置嵌入 (RoPE) 来提升模型的位置信息表示。
在前馈网络 (FFN) 中使用SwiGLU激活函数替代了ReLU。
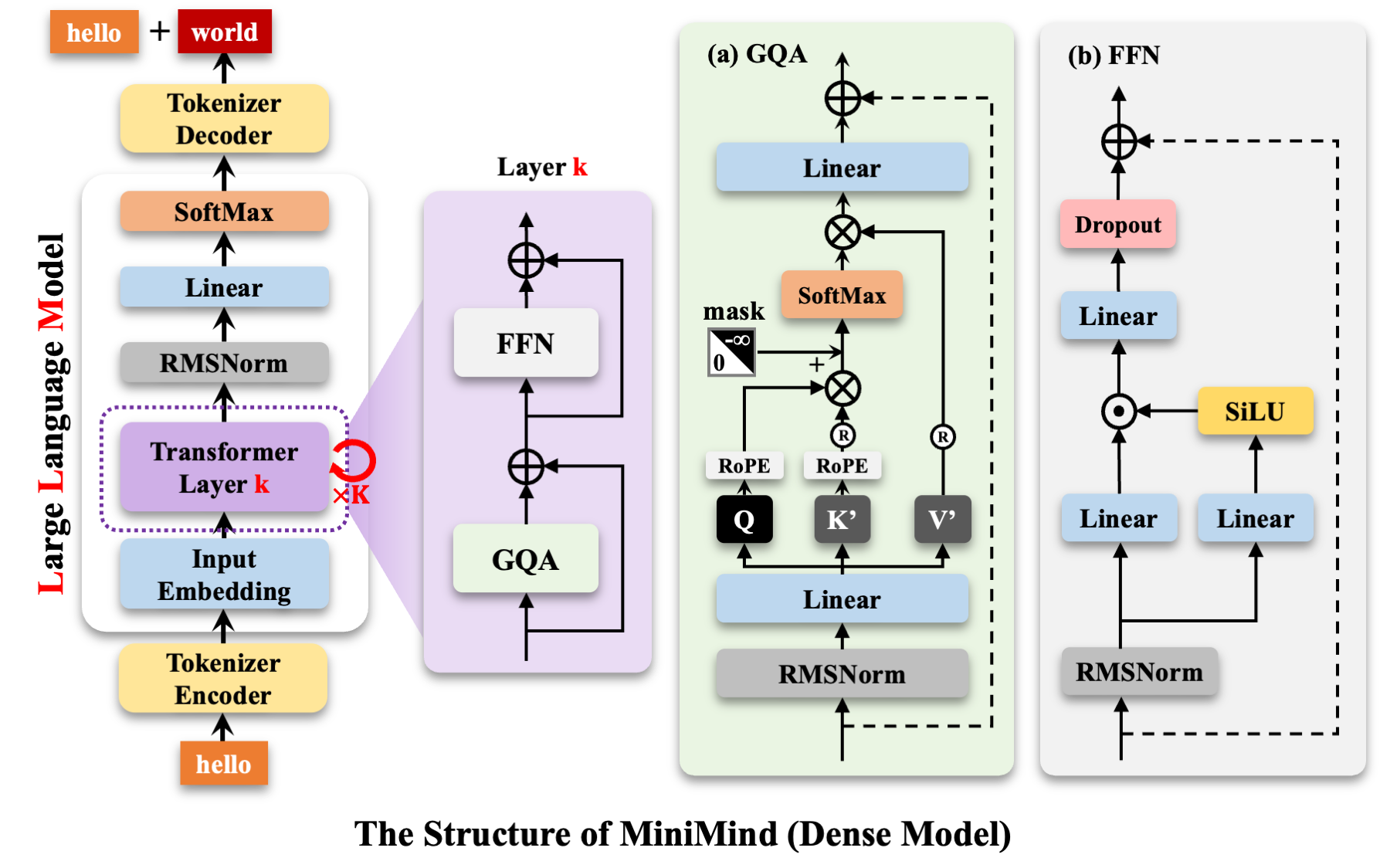
整体训练流程:
- 使用无标注的高质量文本语料数据集 pretrain_hq.jsonl 对模型进行预训练,使大模型在大规模自然语言分布上学习通用语言建模能力,包括基础语义表示、语法结构、上下文依赖关系以及隐式世界知识。 预训练采用自监督学习方式,数据格式如下:
2
3{
"text": "如何才能摆脱拖延症? 治愈拖延症并不容易,但以下建议可能有所帮助..."
}- 使用高质量对话数据对预训练模型进行全量微调,将模型的通用语言能力对齐到人类交互范式,使其具备指令理解、对话建模和合理生成回复的能力。 微调数据采用多轮或单轮对话结构,数据格式如下:
2
3
4
5
6{
"conversations": [
{"role": "user", "content": "请告诉我在中国古代的“四大发明”是什么?"},
{"role": "assistant", "content": "中国古代的“四大发明”是指造纸术、印刷术、火药和指南针...“}
]
}- 在通用对话能力基础上,使用医学领域对话数据对模型进行 LoRA 微调,以较低的参数开销进一步增强模型在医学场景下的语言表达准确性、专业性和领域适配能力。 该阶段的数据格式与全量微调保持一致,仅在内容上聚焦医学领域,例如:
2
3
4
5
6{
"conversations": [
{"role": "user", "content": "我最近怀疑自己得了淋巴癌,想问一下淋巴癌的早期症状有哪些呢?"},
{"role": "assistant", "content": "淋巴癌,也被称为淋巴瘤,是一种起源于淋巴细胞的癌症...“}
]
}- 为进一步提升模型输出的有用性、安全性和符合人类偏好的程度,引入基于偏好比较的数据对模型进行对齐训练。 每条数据包含在相同问题条件下的人类偏好响应(chosen)和非偏好响应(rejected),数据格式如下:
该阶段通过偏好关系对模型进行优化,使模型学会在多个可能回答中倾向于生成更符合人类偏好和价值标准的响应。
2
3
4
5
6
7
8
9
10{
"chosen": [
{"content": "Qusstion", "role": "user"},
{"content": "good answer", "role": "assistant"}
],
"rejected": [
{"content": "Question", "role": "user"},
{"content": "bad answer", "role": "assistant"}
]
}

理论讲解
模型结构
首先关于 transformer 的介绍可见 搜广推学习之路(二),下面只介绍不同于 Transformer 的部分。
RMSNorm
首先 Norm 全拼为 Normalization,Norm 可以消除数据间的尺度差异,降低参数尺度过大或过小对训练过程造成的不稳定性,并有效缓解梯度爆炸或消失现象。 RMSNorm 是由 LayerNorm (L-N) 改进而来,所以我们先介绍一下 LayerNorm,对于向量 x = (x1, x2, …, xn) 进行“中心化”和“缩放”的操作,使输入的数据的分布近似于标准的正态分布: 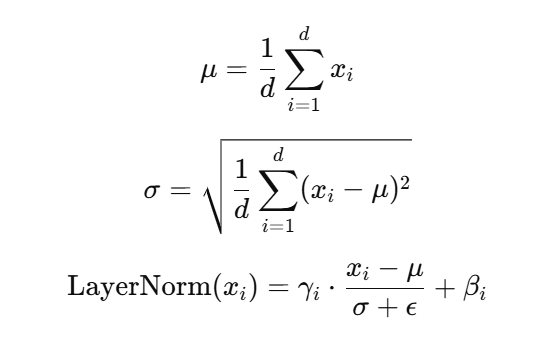 其中γi, βi是可学习的参数。
其中γi, βi是可学习的参数。
RMSNorm 在 LayerNorm 的基础上进行了简化,移除了均值项,即只对数据进行“缩放”操作,而不进行“中心化”。相较于 LayerNorm,在保持性能相当的前提下显著提升了计算效率。RMSNorm的公式为: 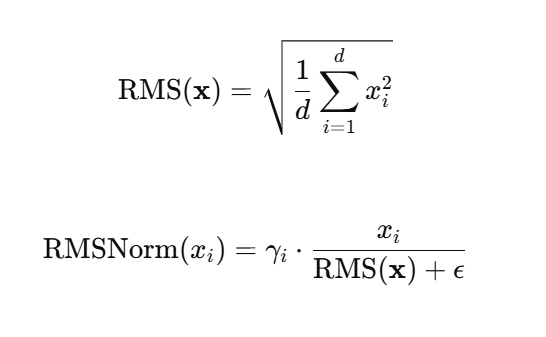
1 | |
RoPE
参考:https://www.zhihu.com/tardis/bd/art/647109286
具体推导过程不在详细解释,在参考文章中已经十分清晰了。我们这里只解释在 Transformer 中怎么使用 RoPE编码。
这里使用 d 维的 x 向量笼统表示一个 Query 或 Key 向量,x 向量的位置为 m,RoPE 对于 x 向量,两两分为一组,例如将 [x1, x2, x3, x4] 看作 [(x1, x2), (x3, x4)],然后将每组向量旋转 mθi 得到加入位置信息的新向量。θi的计算方法与最初 Transformer 中的计算方法一致: 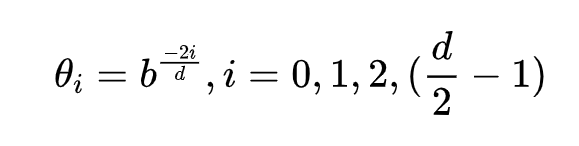 其中 b 为基数,一般取10000。
其中 b 为基数,一般取10000。
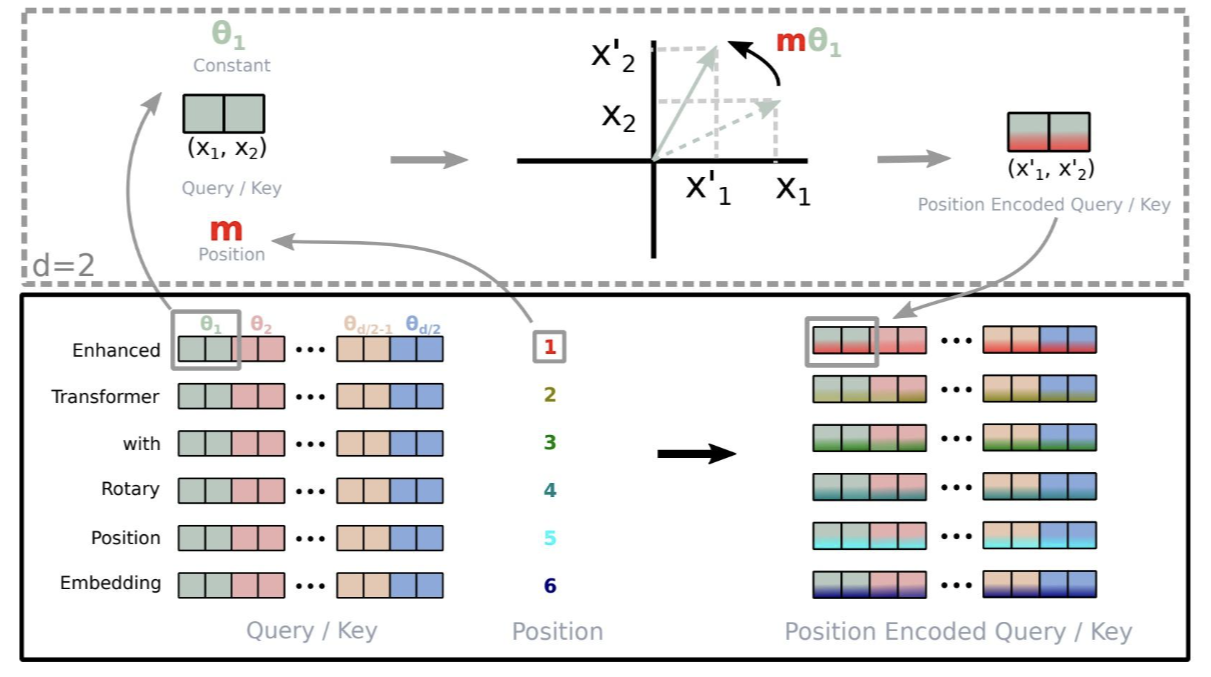
RoPE 通过将位置编码与旋转变换结合起来,能够使 Query 和 Key 向量在计算时考虑到词与词之间的相对位置,而不是单纯地依赖每个词的绝对位置。同时 RoPE 可以通过旋转矩阵来实现位置编码的外推,即可以通过旋转矩阵来生成超过预训练长度的位置编码。这样可以提高模型的泛化能力和鲁棒性。
SiLU
SiLU 的定义为: 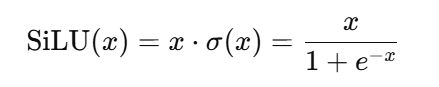
其中 σ(x) 为sigmoid 函数,SiLU 函数图像如下: 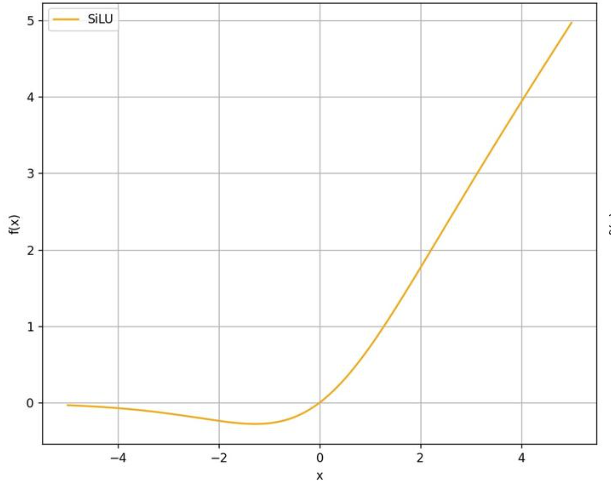
相较于 ReLU 在负区间对输入进行硬截断并置零,SiLU 对负值进行平滑抑制,使输出连续地衰减至零;同时,SiLU 在整个输入域上连续可导,从而使梯度更新更加稳定。
- x << 0:σ(x) ≈ 0,所以 SiLU(x) 近似为0
- x ≈ 0:SiLU(x) 近似为0
- x >> 0:σ(x) ≈ 1,所以 SiLU(x) 近似为x 在 x=0 附近的局部区域,σ(x) 从 0 到 1 连续变化,使得 SiLU 对输入起到一种平滑的门控作用。
在 FFN 中,输入被分为左右两条分支。左分支作为数据分支,负责提供原始的信息;而右分支则是门控分支,用于生成控制信号。右分支通过 SiLU 激活函数,对有用信息进行强化,同时抑制噪声,确保网络能够有效地选择和保留重要特征。 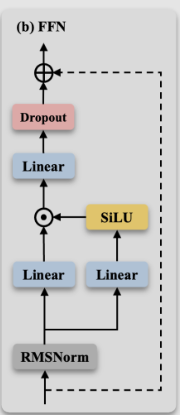
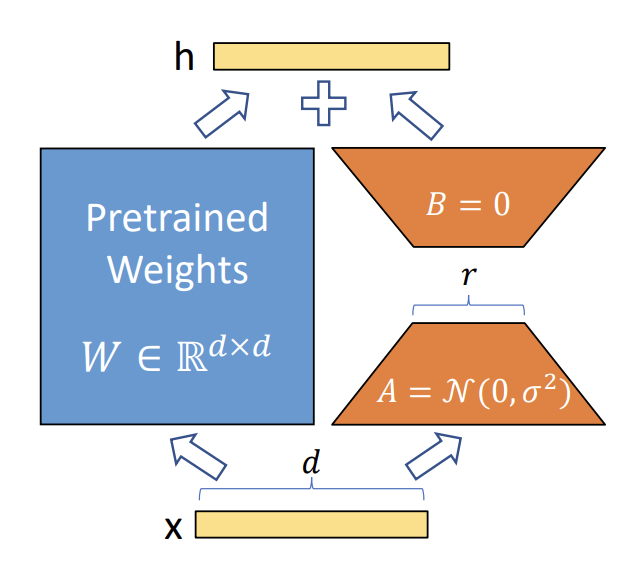
LoRA
参考:https://www.zhihu.com/tardis/zm/art/623543497?source_id=1003
LoRA (Low-Rank Adaptation) 是参数高效微调 (Parameter-Efficient Fine-Tuning,PEFT) 技术中的一种,PEFT技术的整体思想是冻结大模型的大部分参数,再引入一小部分可训练的参数作为适配模块进行微调训练,以达到节省大模型微调时显存占用开销的目的。
如下图所示,h = xW,其中 W 是预训练得到的权重矩阵,当我们在进行全量微调时,需要对 W 矩阵进行更新,参数量为 d x d。LoRA 的方法即引入 A 和 B 两个低维矩阵,A的维度为 r x d;B 的维度为 d x r (r << d)。在进行训练时,就可以令 W 保持不变,只对矩阵 A 和 B 进行更新,得到 ΔW = BA,然后经 LoRA 微调后的权重矩阵就为 W + ΔW,此时需要更新的参数量为 2 x d x r。最终h = xW + BAx
1 | |
DPO
参考:https://haxxorcialtion.github.io/posts/LLM%E5%BC%BA%E5%8C%96%E5%AD%A6%E4%B9%A0%E6%B7%B1%E5%BA%A6%E8%A7%A3%E6%9E%90-%E4%BB%8E%E5%9B%B0%E6%83%91%E5%88%B0%E7%90%86%E8%A7%A3.html
- RLHF(人类反馈强化学习):一种训练范式 / 整体流程
- SFT -> 训练奖励模型 (Reward Model, RM) -> 强化学习算法优化策略模型
- PPO:一种通用强化学习算法,用于 RLHF 第三步
- DPO:跳过 Reward Model + PPO,直接用偏好数据训练
PPO
在 DPO 之前,我们先介绍 PPO 算法,PPO 算法中涉及到了四个模型:
- Actor/Policy Model: πθ,用 SFT 后的模型作为初始模型,通过 PPO 训练调整参数,得到最终的模型,用于生成更符合人类偏好的回答(需要训练)
- Reference Model: πref,参考模型,通过 KL 散度约束 Actor Model 不偏离初始分布(冻结)
- Reward Model: R(x, y),奖励模型,用于给当前回答打分(冻结)
- Critic/Value Model: V(s_t),价值函数模型,用于估计在状态 st 下的期望总收益,作为优势函数的基线(需要训练)