搜广推学习之路(四)
推荐系统课程
王树森推荐系统课程
排序
粗排和精排的原理类似,只是模型大小不同,所以下面讲解不具体区分粗排和精排。
排序的依据:排序模型预估点击率、点赞率、收藏率和转发率等多种分数,然后再融合这些预估分数,根据融合后的分数做排序和截断。
多目标模型
如图所示,多目标模型的输入是各种特征的组合,用户特征(用户ID和用户画像)、物品特征(物品ID、物品画像和作者信息)、统计特征(用户统计特征和物品统计特征,过去30天用户曝光、点击和点赞了多少笔记;过去30天物品获得了多少次曝光、点击和点赞)和场景特征(时间、地点)。模型最后得到四个输出预估值,均为0-1之间的数值,在训练时,使用交叉熵损失函数。目标值为0或1,0表示无交互,1表示有交互。 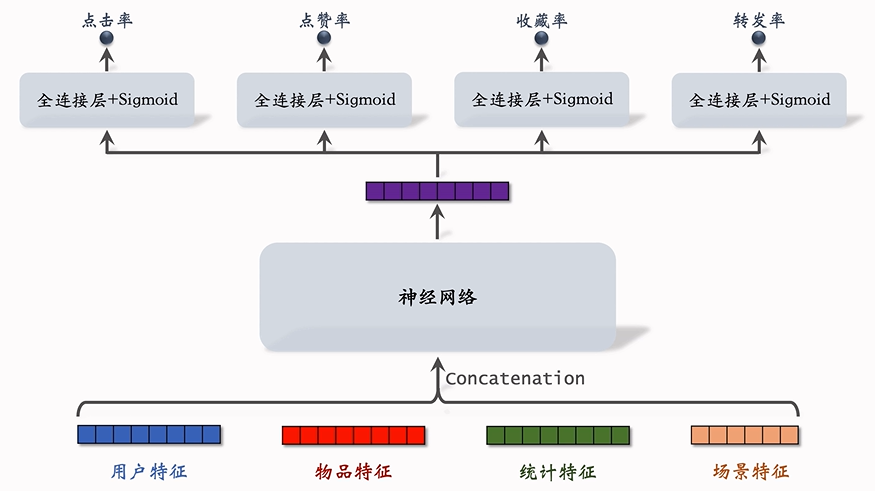

而在训练时存在很多问题,重点讲解类别不平衡,正样本少,负样本多,解决方案是进行负样本降采样,只保留一部分的负样本,通过减少负样本的数量,使得正负样本数量平衡,也可以节约计算。
在得到四个率的预估值后,需要先对其进行校准,才可以进行排序。因为我们为了解决类别不平衡的问题,对负样本进行了降采样,使用αn个负样本,α ∈ (0, 1)是采样率,n是负样本数量。因为负样本减少,所以会导致得到的预估点击率大于真实点击率,因此需要进行预估值校准。α越小,负样本越少,点击率的预估就越高。 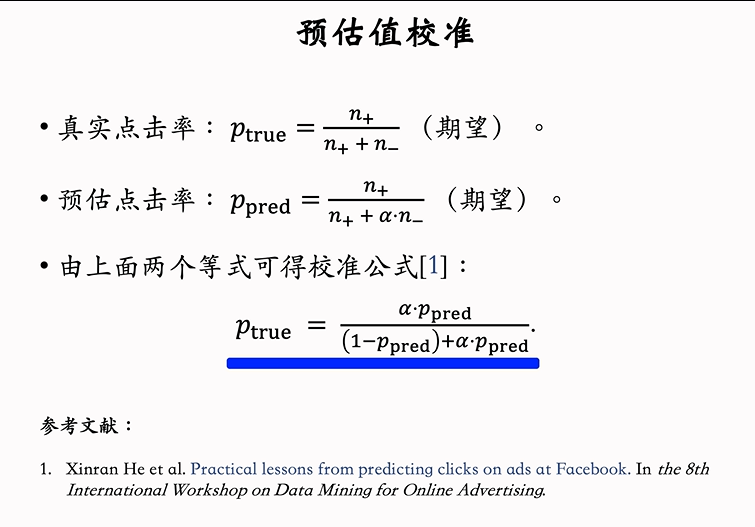
Multi-gate Mixture-of-Experts (MMoE)
MMoE模型的核心思想就是使用多个专家(Experts)网络来提取特征,再根据任务的不同,通过门控网络(Gate)来加权不同专家的输出,从而进行不同任务的预测。根据图中的例子给出具体解释:
- 专家网络(Experts):假设我们有三个专家,每个专家通过不同的非线性变换学习输入特征的不同表示。(三个神经网络的参数不共享)
- 门控网络(Gates):MMoE 为每个任务(如点击率预测、点赞率预测)设置一个门控网络。每个门控网络根据输入的特征向量,动态地为每个专家分配不同的权重(即每个专家的输出对任务的贡献程度)。(即神经网络+softmax函数,得到三个专家的权重)
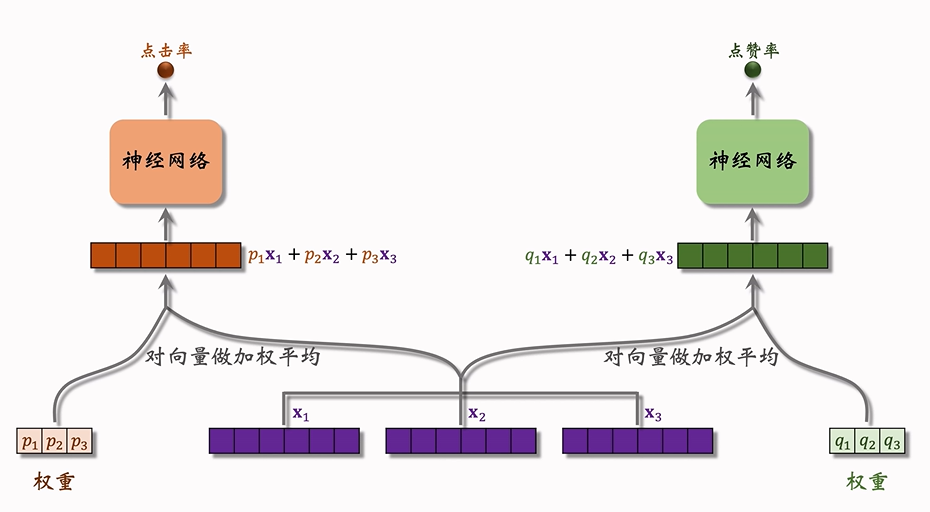
- 加权平均:对每个任务的专家输出进行加权平均。这个加权平均是通过门控网络为每个专家分配的权重进行的。具体来说,专家输出的三个信息向量分别为 (x1, x2, x3),而门控网络为每个任务分配的权重分别是 (p1, p2, p3) 和 (q1, q2, q3)。
- 任务预测:加权平均后的向量作为输入,进入任务特定的预测层,进行点击率预测、点赞率预测等。
这种结构可以在不同任务之间共享特征表示,同时避免任务之间的干扰,提升模型的表现。 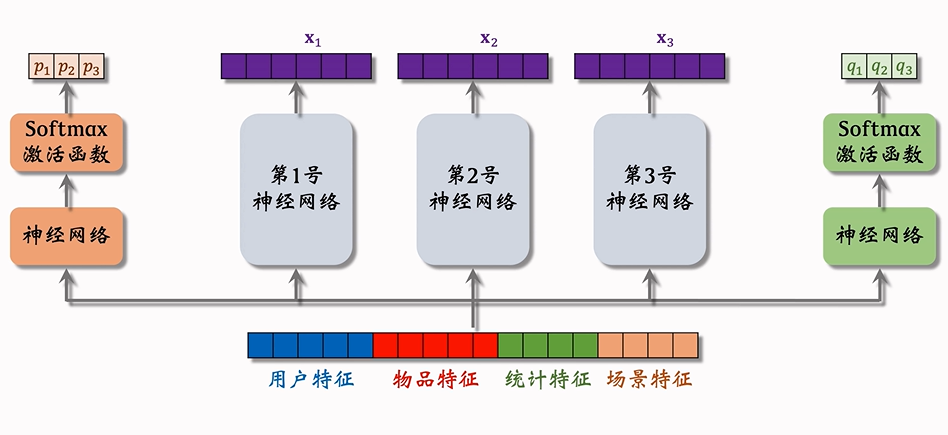
MMoE中存在极化的问题,即Softmax输出值一个接近为1,其他的接近0。如下图所示,左侧输出为(0, 0, 1)那么会导致在后续的预测任务中只使用了三号专家的向量,而右侧输出(0, 1, 0),只使用了二号专家的向量。这样就会导致其他专家未发挥作用,那么MMoE就没有意义了。 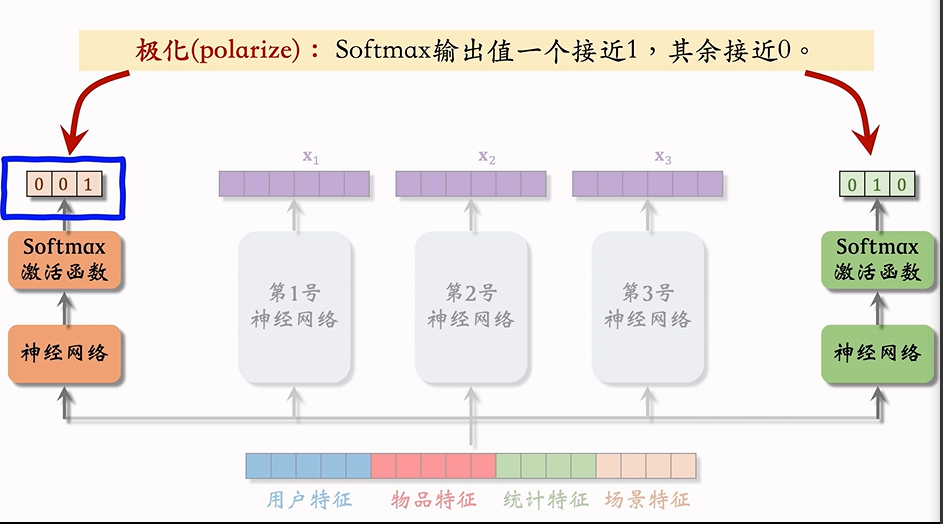
解决方案也比较简单:在训练阶段对 Softmax 的输出使用 Dropout。这样 Softmax 输出中的每个权重都有 10% 的概率被 Mask 掉。如果门控网络出现“极化”,即过度依赖某一个专家,当该专家的权重在训练时被随机 Mask 掉,就会导致当前预测效果变差,从而迫使模型学会在其他专家上分配合理的权重。通过这种方式,可以有效避免只使用少数专家的问题,促使所有专家都参与训练,提高模型的鲁棒性和泛化能力。
预估分数的融合


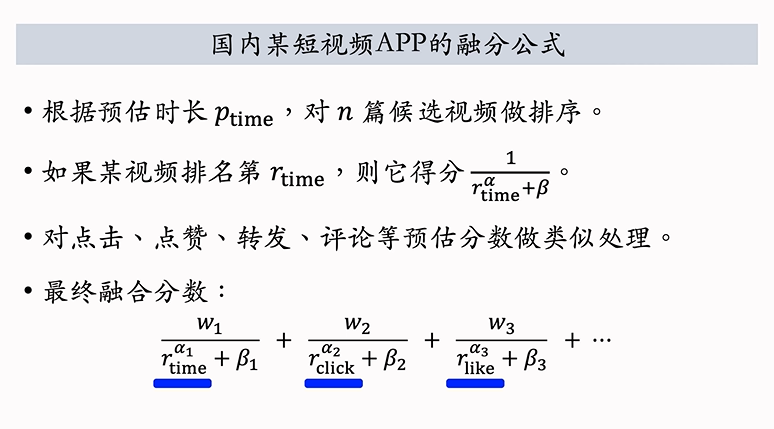

视频播放建模
图文笔记排序依据点击、点赞、收藏、转发、评论等就可以,但对于视频来说还有播放时长和完播这两个指标很重要,用户对一个视频没有点赞收藏,但看完了,也能说明用户对该视频感兴趣。
设模型的群连接层输出一个预估值z,对z做sigmoid变换得到 p,模型的训练目标为y = t/(1 + t),其中t为实际观测的播放时长。训练最小化p和y的交叉熵损失,观察得到,若p=y,那么exp(z)=t,所以在推理时候,就使用exp(z)作为播放时长的估计。 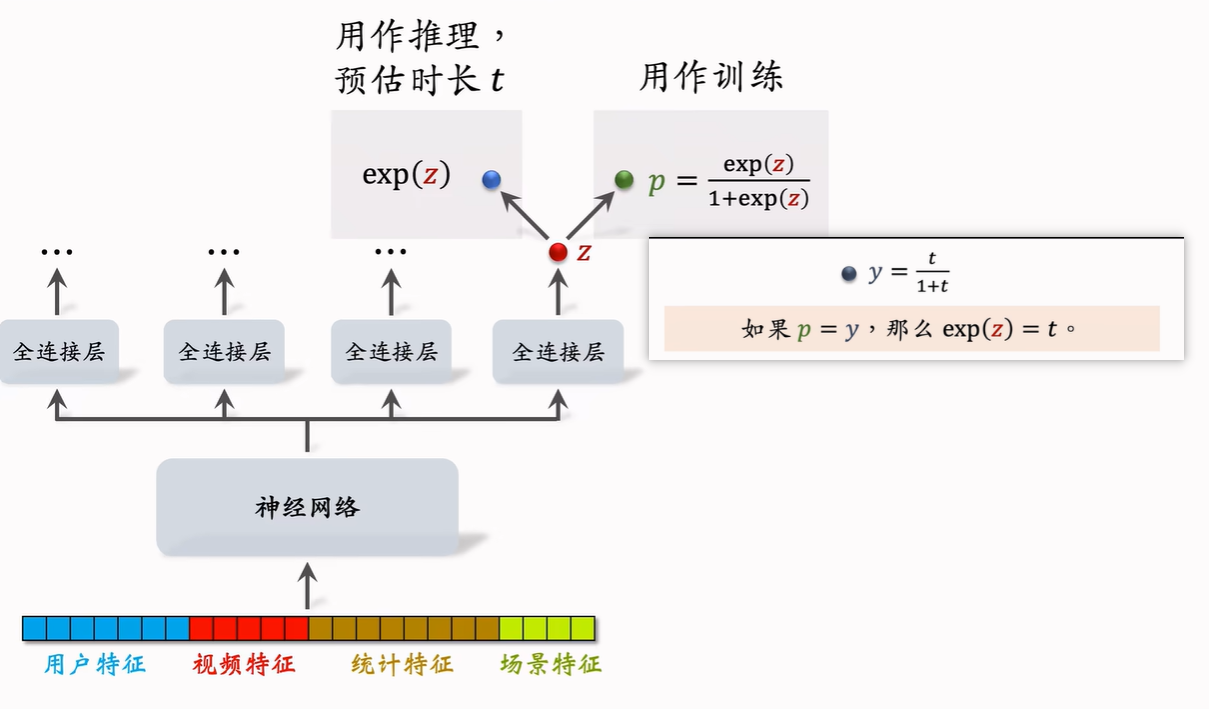
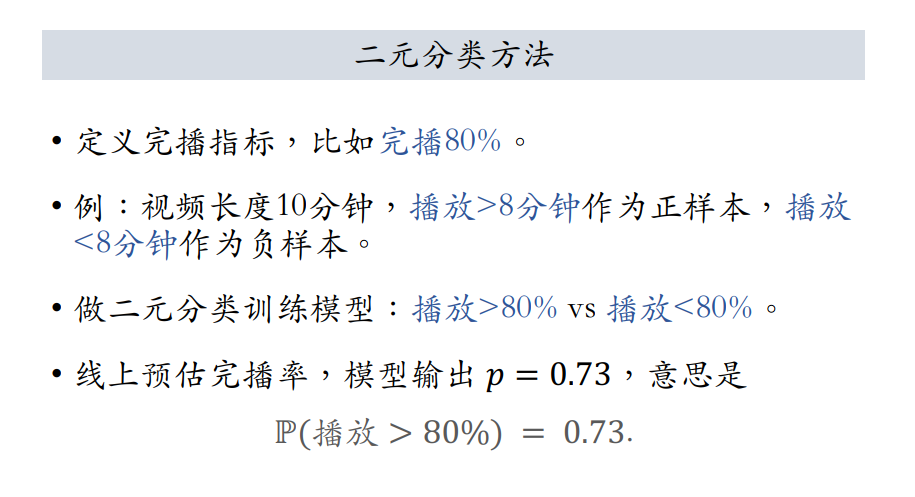
对视频完播有两种建模方法,回归和分类:
- 回归:

- 分类:
但实际上,并不可以直接将预估完播率直接用于融分公式中,因为完播率会随视频时长的增加而降低,直接使用预估完播率,会对短视频友好而对长视频不友好,所以使用函数f拟合完播率曲线,然后对预估完播率做调整得到最终完播率,作为融分公式中的一项。 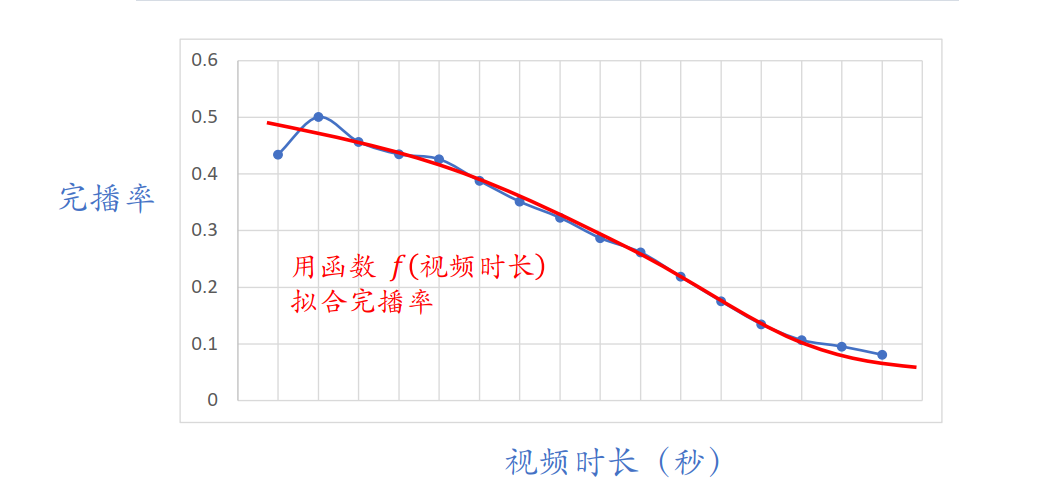
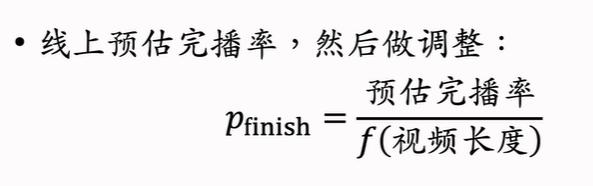
排序模型的特征
在召回和排序中,都需要用到用户和物品的多维特征,主要包括:
- 用户画像(User Profile)
- ⽤户 ID(在召回、排序中做 embedding)
- ⼈⼝统计学属性:性别、年龄
- 账号信息:新⽼、活跃度……
- 感兴趣的类⽬、关键词、品牌
- 物品画像(Item Profile)
- 物品 ID(在召回、排序中做 embedding)
- 发布时间(或者年龄)
- GeoHash(经纬度编码)、所在城市
- 标题、类⽬、关键词、品牌……
- 字数、图⽚数、视频清晰度、标签数……
- 内容信息量、图⽚美学……
- 用户统计特征
- ⽤户最近30天(7天、1天、1⼩时)的曝光数、点击数、点赞数、收藏数……
- 按照笔记图⽂/视频分桶。(⽐如最近7天,该⽤户对图⽂笔记的点击率、对视频笔记的点击率。)
- 按照笔记类⽬分桶。(⽐如最近30天,⽤户对美妆笔记的点击率、对美⾷笔记的点击率、对科技数码笔记的点击率。)
- 笔记统计特征
- 笔记最近30天(7天、1天、1⼩时)的曝光数、点击数、点赞数、收藏数……
- 按照⽤户性别分桶、按照⽤户年龄分桶……
- 作者特征:发布笔记数、粉丝数、消费指标(曝光数、点击数、点赞数、收藏数)
- 场景特征(Context)
- ⽤户定位 GeoHash(经纬度编码)、城市
- 当前时刻(分段,做 embedding)
- 是否是周末、是否是节假⽇
- ⼿机品牌、⼿机型号、操作系统
 log(1+x)变换针对长尾数据,可以处理异常值,因为一般点击率、曝光率可能就几百几千,但遇到爆贴时,数字就很大了。当然,在做特征处理时,除了要考虑异常值还需要考虑特征覆盖率。实际上,大多数特征无法覆盖100%样本(比如用户不写年龄、设置隐私权限等)。显然,提高特征覆盖率可以让精排模型更准,所以在特征处理时还需要考虑如何做缺失值的补全。
log(1+x)变换针对长尾数据,可以处理异常值,因为一般点击率、曝光率可能就几百几千,但遇到爆贴时,数字就很大了。当然,在做特征处理时,除了要考虑异常值还需要考虑特征覆盖率。实际上,大多数特征无法覆盖100%样本(比如用户不写年龄、设置隐私权限等)。显然,提高特征覆盖率可以让精排模型更准,所以在特征处理时还需要考虑如何做缺失值的补全。
粗排
虽然不具体区分粗排和精排,但前序内容主要描述精排模型,下面单独介绍粗排模型。 首先比较一下粗排和精排: 粗排给几千篇笔记进行打分,所以单次推理代价必须要小,精排模型的准确率不高,而牺牲准确率是为了保证线上推理速度足够快,快速从几千篇笔记中筛选出几百篇。
精排给几百篇笔记打分,单次推理的代价很大也没有关系,精排模型规模可以很大,结构可以很复杂,牺牲计算要让最后预估的准确性足够高。 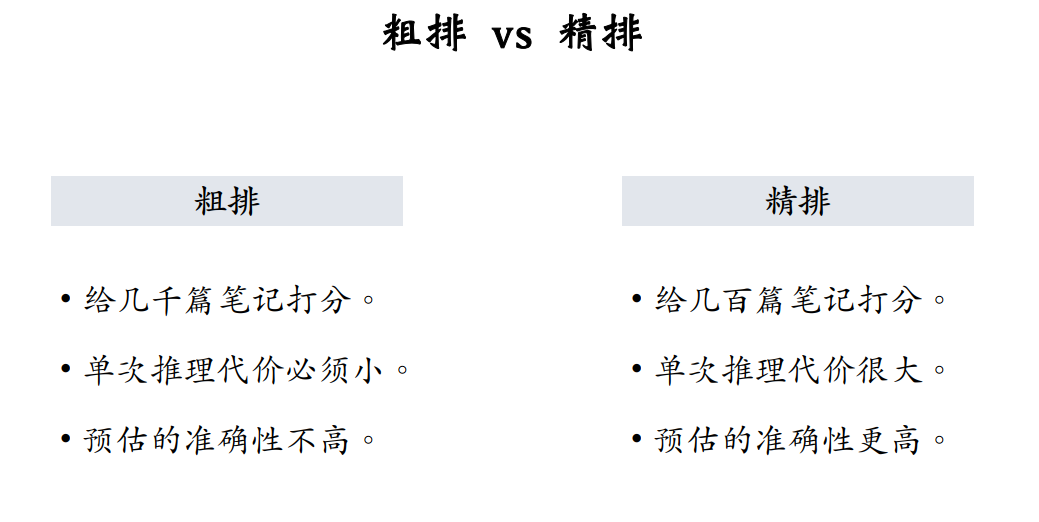
回顾一下精排模型和双塔模型,精排模型是前期融合:先对所有特征做 concatenation,再输⼊神经⽹络。精排模型线上推理代价大,因为有n个物品的话,需要整个模型做n次推理。(用户改变,输入也就改变,每次都要进行推理,不能存储在数据库中) 而双塔模型是后期融合:把⽤户、物品特征分别输⼊不同的神经⽹络,不对⽤户、物品特征做融合。双塔模型线上计算量小,因为用户塔只需要做一次推理来计算用户的表征,物品表征可事先存储在向量数据库中,直接调用。但双塔模型预估准确率不如精排模型。 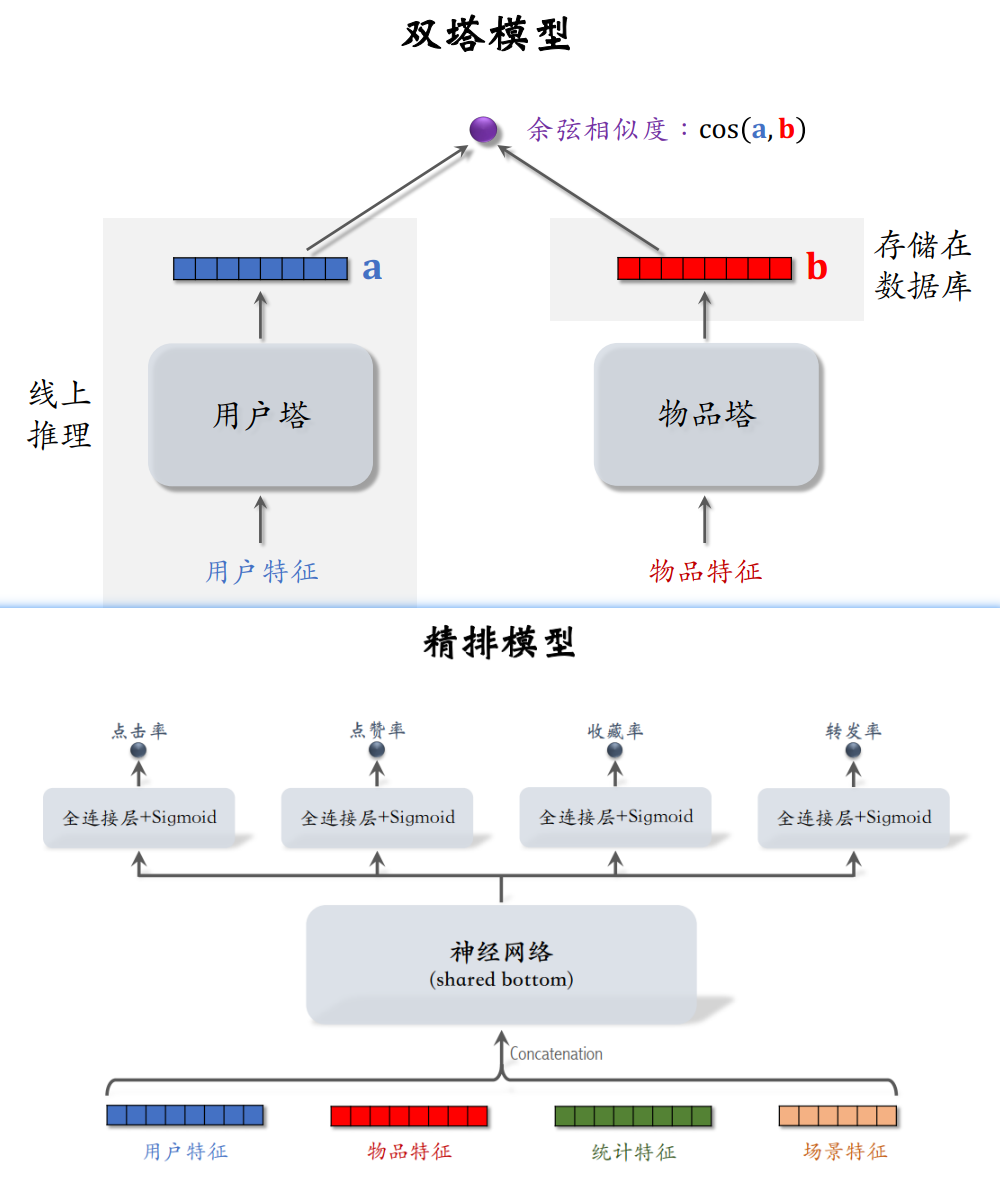
而小红书的粗排模型是三塔模型,效果介于精排模型和双塔模型之间。 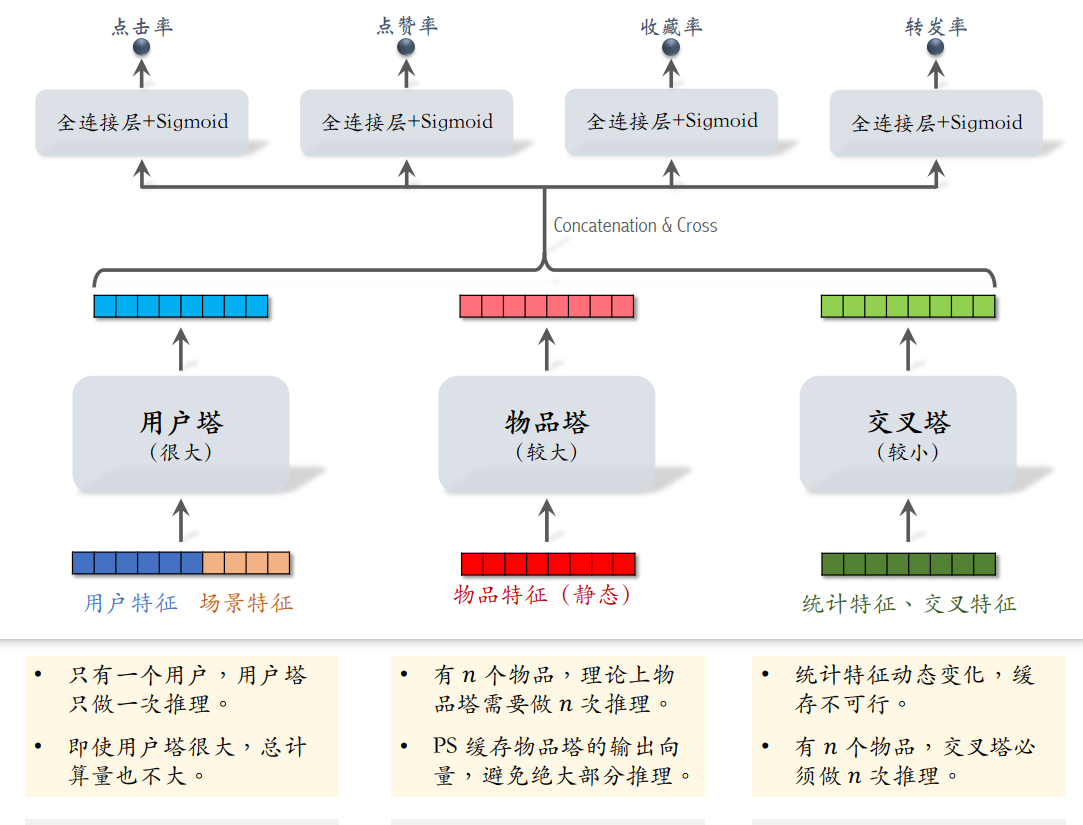
粗排的计算量大部分都在上层网络,在下层网络的三塔中,用户塔每次对用户做一次推理就够了,物品塔可事先将输出向量存储在数据库中,避免线上推理,只有遇到新物品是 才需要进行一次推理。交叉塔的输入是用户和物品的统计特征,还有用户和物品特征的交叉。而统计特征会实时动态变化,每当一个用户发生点击等行为,它的统计特征就会发生变化,每当一个物品获得曝光和交互,它的点击次数、点击率等指标就会发生变化。所以交叉塔的输入会实时更新,n个物品要做n次推理,所以交叉塔一般都比较小,保证计算速度足够快(通常来说交叉塔只有一层,宽度也比较小)。有n个物品,模型上层需要做n次推理。
特征交叉
Factorized Machine (FM)
如下展示,在线性模型中,预测是特征的加权和,但这是不够的,我们需要将特征进行交叉,从而使模型预测更加准确。 
因此,我们在线性模型的基础上添加二阶交叉特征,但此时如果d很大,那么计算量就太大了,所以采取操作,将交叉特征的系数矩阵U进行矩阵分解,将 dd 维的矩阵转化为 dn 维矩阵乘 n*d 维矩阵(n < d)。把⼆阶交叉权重的数量从 O(d2) 降低到 O(kd) 。 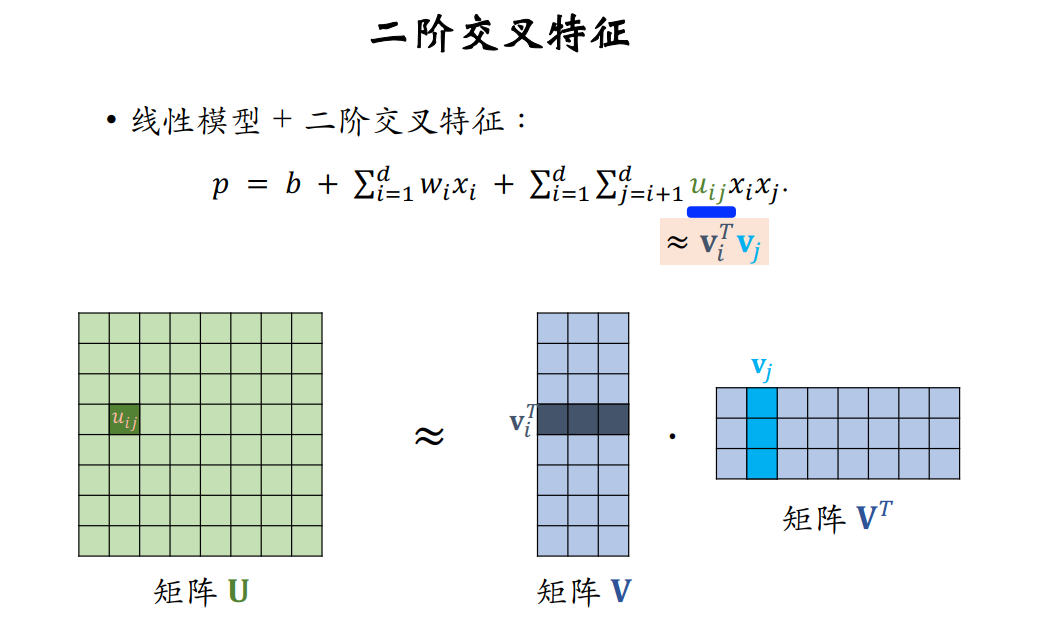
深度交叉网络 (DCN)
如图,在双塔模型、精排模型和MMoE模型中,可以使用任意神经网络架构,在这节我们将介绍深度交叉网络,深度交叉网络由一个深度网络和一个交叉网络组成,其中交叉网络的基本组成单元又是交叉层。下面我们将介绍交叉层。 
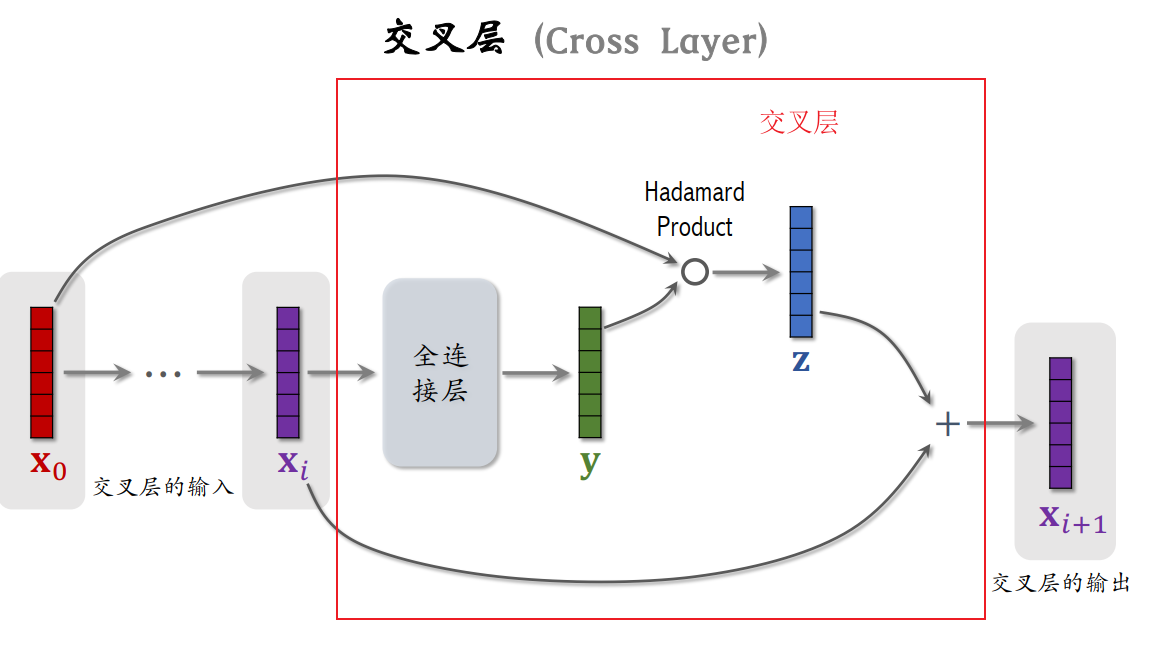
交叉层的基本流程:
- 初始输入向量x0,经过若干层神经网络后输出向量xi,这两个都是交叉层的输入
- 将向量xi输入全连接层,输出向量y
- 初始输入x0和向量y的Hadamard 乘积(对应位置逐个元素相乘)得到向量z
- 将向量z和xi加和得到交叉层的输出
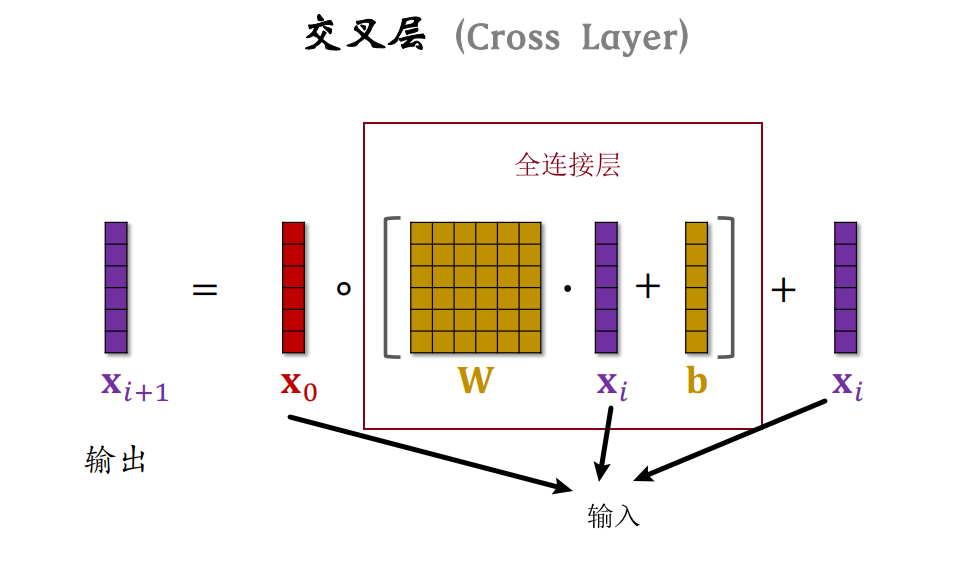
而交叉网络就是由交叉层构成的,如下图所示为Cross Network V2的基本架构: 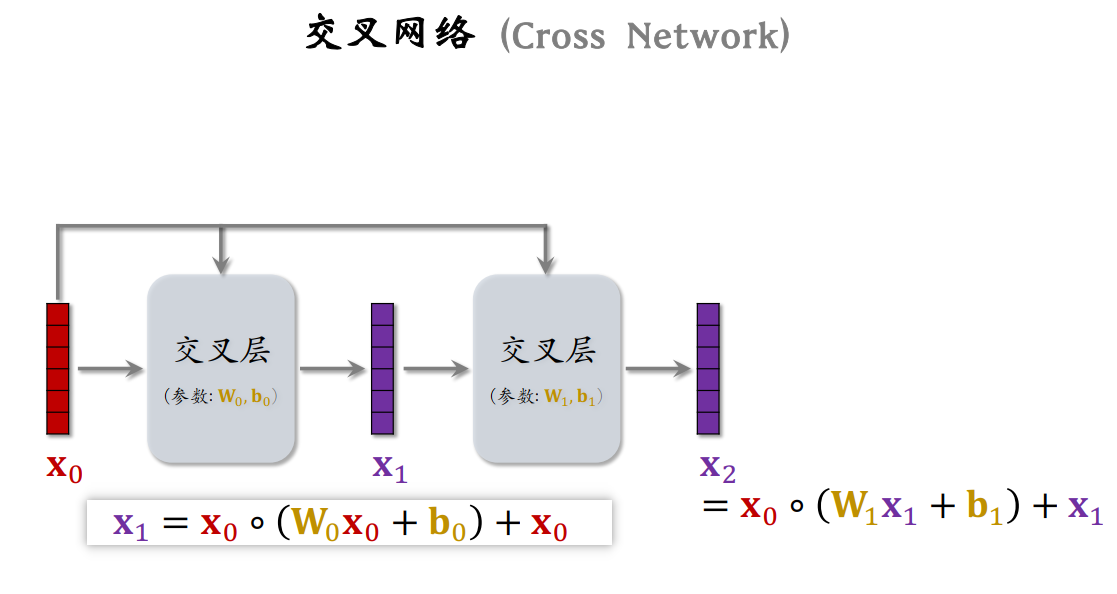
深度交叉网络的就是将特征拼接起来,分别输入全连接网络和交叉网络,将得到的两个向量拼接后输入全连接层,得到最后的输出。 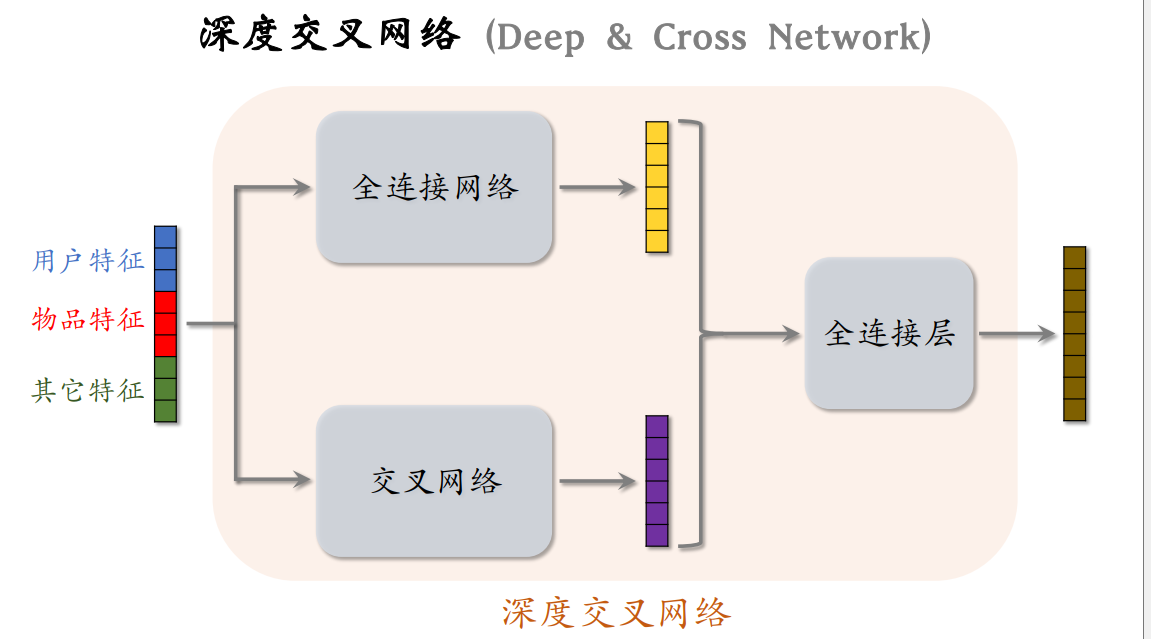
LHUC网络结构
LHUC模型只可以用于精排。用户特征经过神经网络最后输出时会使用2 sigmoid,这样用户特征与物品特征hadamard乘时可以起到放大抑制保持作用,输出范围为[0, 2],0表示抑制,1表示保持,2表示放大。 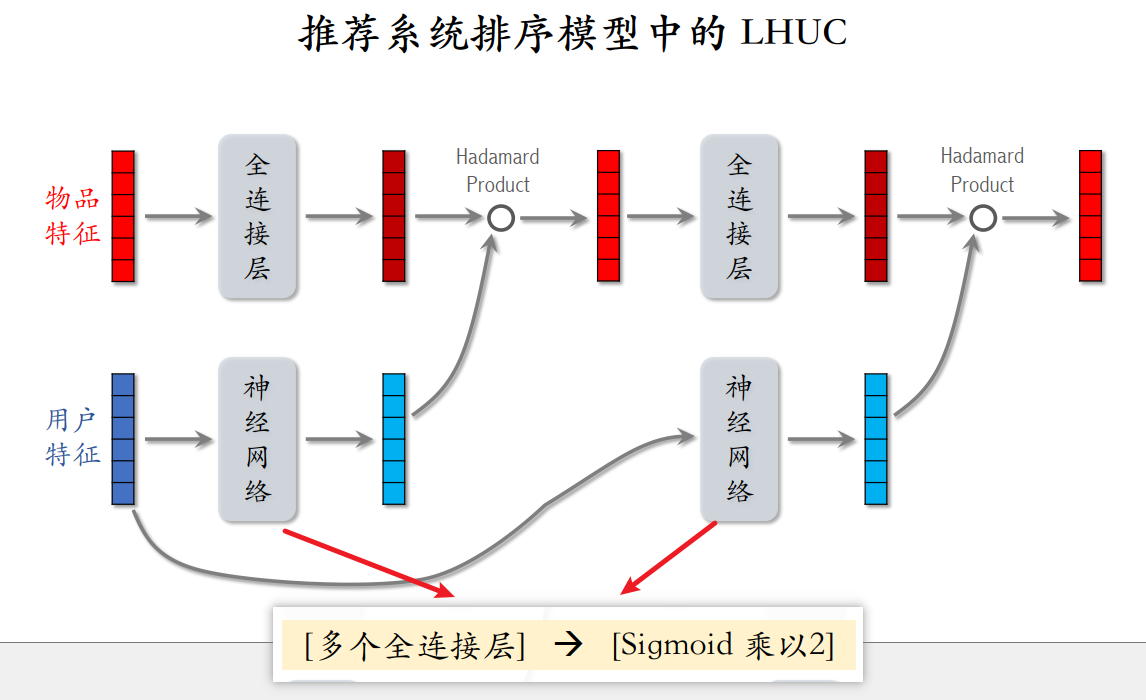
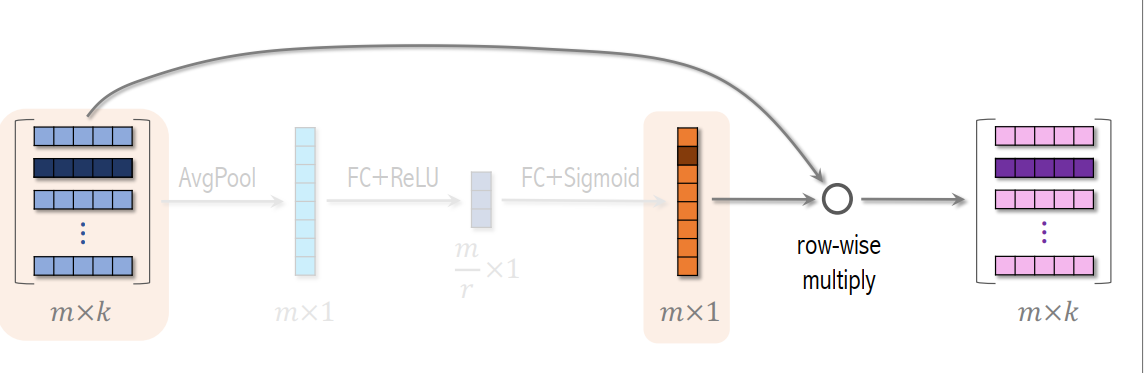
SENet
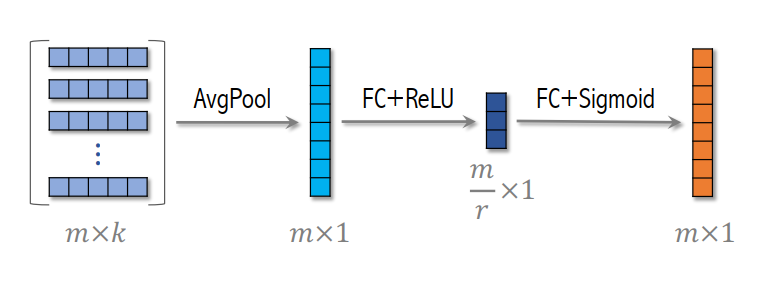
SENet 能够对特征进行自适应(动态)加权。其整体流程如图所示:首先将输入特征通过 Embedding 映射到一个 k 维特征向量;随后对该特征向量进行 全局平均池化(AvgPool),将其压缩为一维的通道描述向量;接着通过一系列变换,并结合 Sigmoid 函数,将通道响应映射到 ([0,1]) 区间,得到对应的权重系数;最后,将该权重与最初的 k 维特征向量逐通道相乘,从而获得加权后的特征表示。注意embedding向量的维度可以不同。 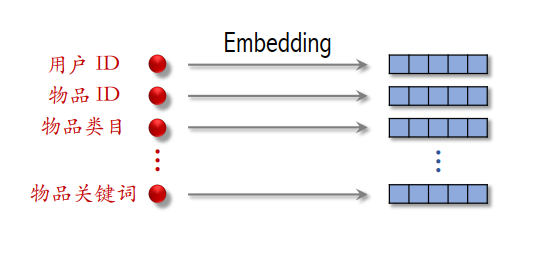
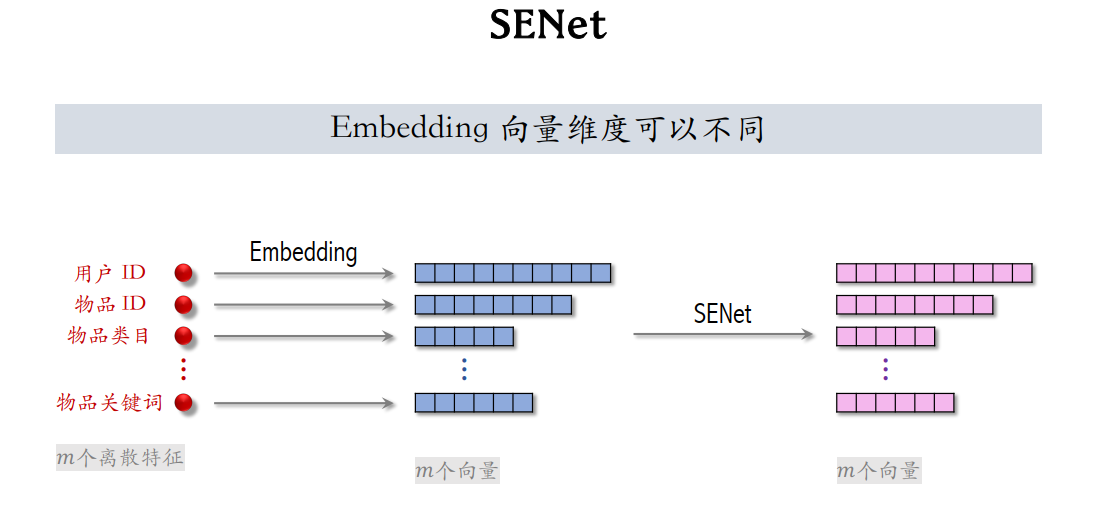
Field:对于每个特征,如用户ID,embedding是64维向量,这64维向量算是一个field
SENet本质就是对离散特征做field-wise加权,每个field获得相同的权重,有m个fields,那么权重向量就是m维。
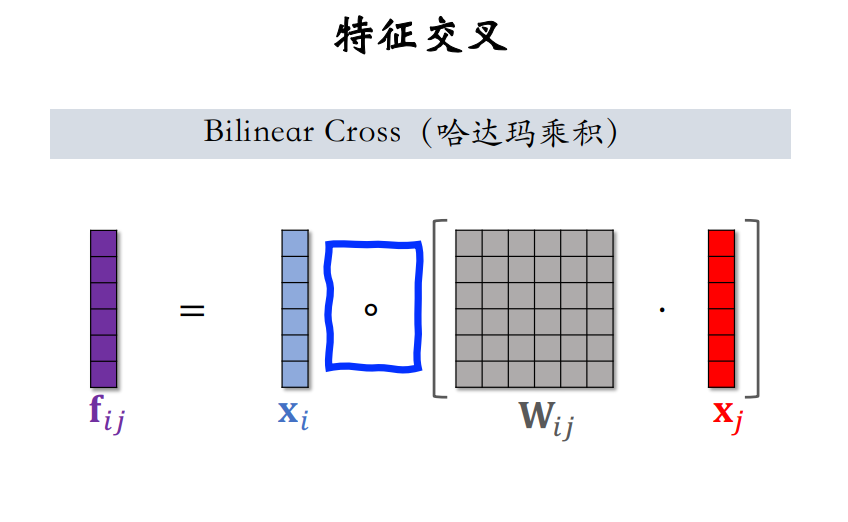
接下来介绍Field间的特征交叉,可以求两特征的内积或哈达玛乘积,如下图所示: 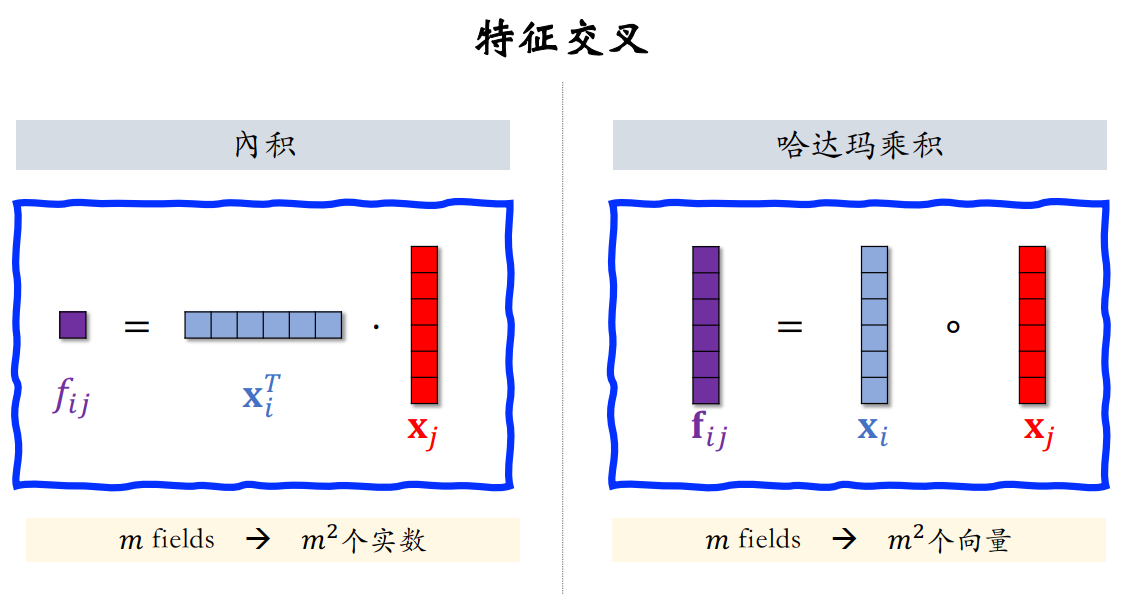
但直接求内积或哈达玛乘积都要求两个特征embedding向量是同维的,因此我们通过Bilinear Cross来解决不同维特征的交叉问题。 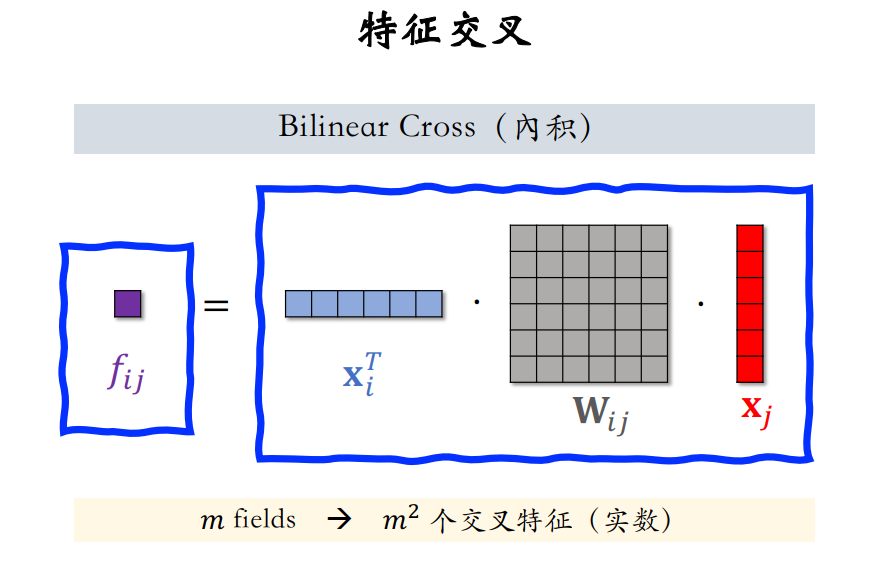
FiBiNet
将SENet与Bilinear Cross结合起来就得到FiBiNet。 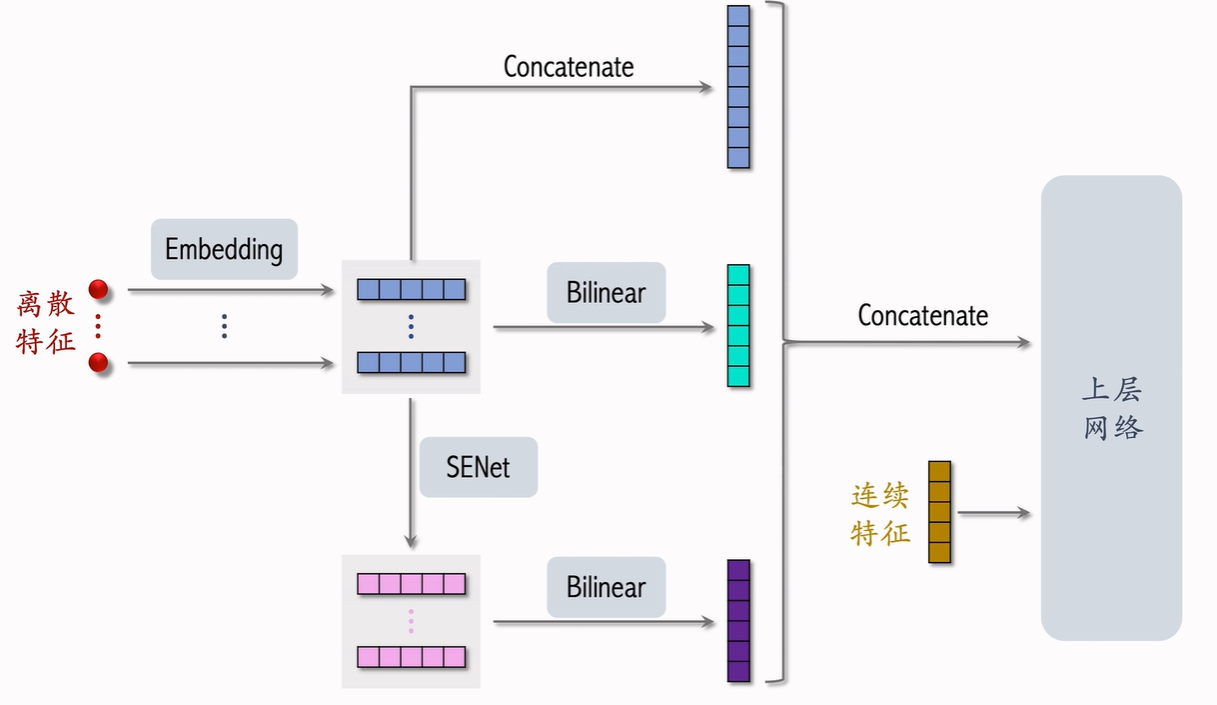
用户行为序列建模
将用户行为序列叫做LastN,指用户最近交互过的N个物品。下面以用户特征为例,讲解用户特征的LastN序列,用户的LastN是指最近交互过的LastN个物品,对 LastN 物品 ID 做 embedding,得到 n 个向量。把 n 个向量取平均,作为⽤户的⼀种特征,表示物品过去感兴趣的N个物品,适⽤于召回双塔模型、粗排三塔模型、精排模型。 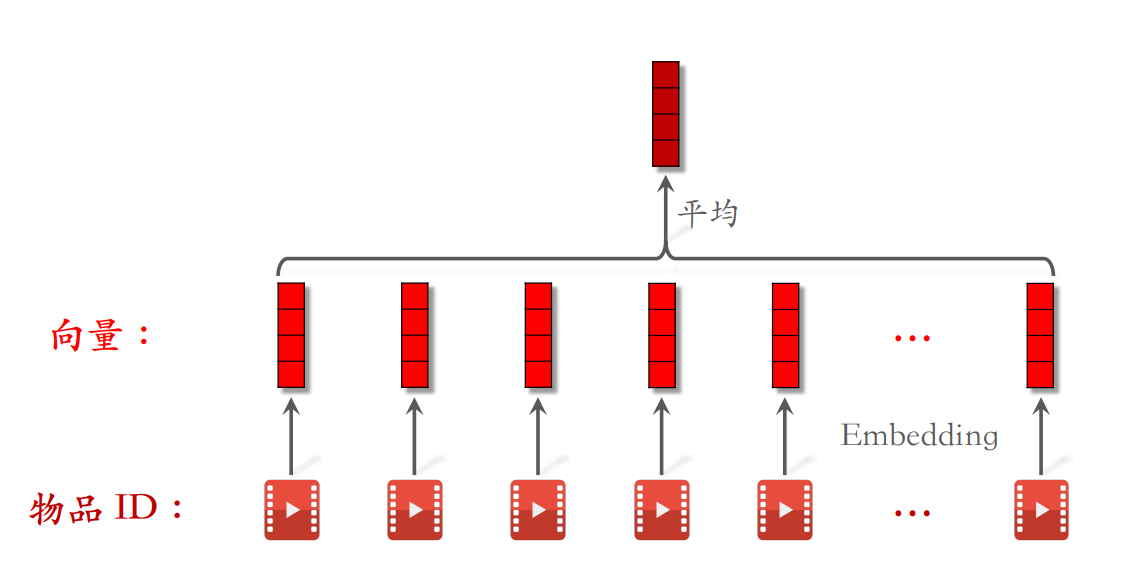
DIN模型
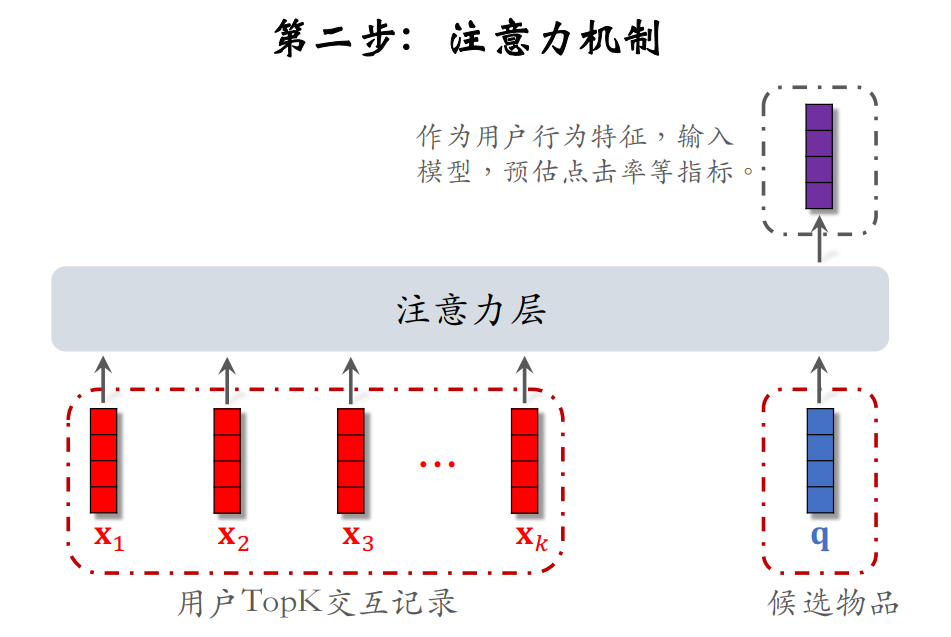
DIN模型是使用加权平均来替代平均,即使用注意力机制。而权重就是候选物品与LastN物品的相似度。 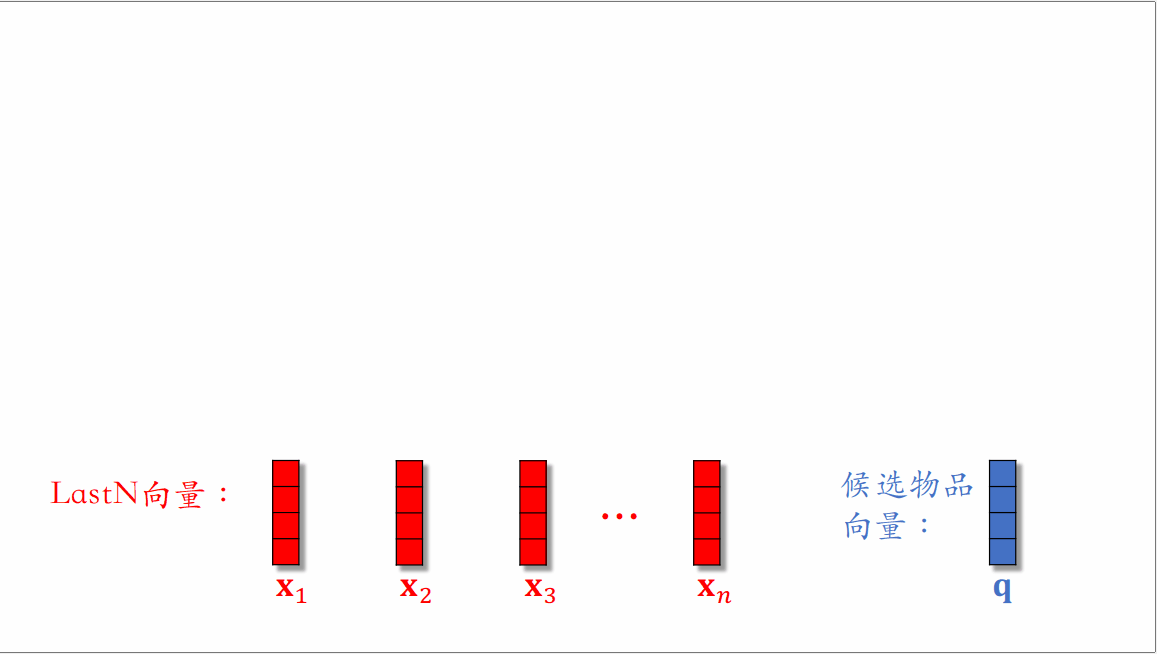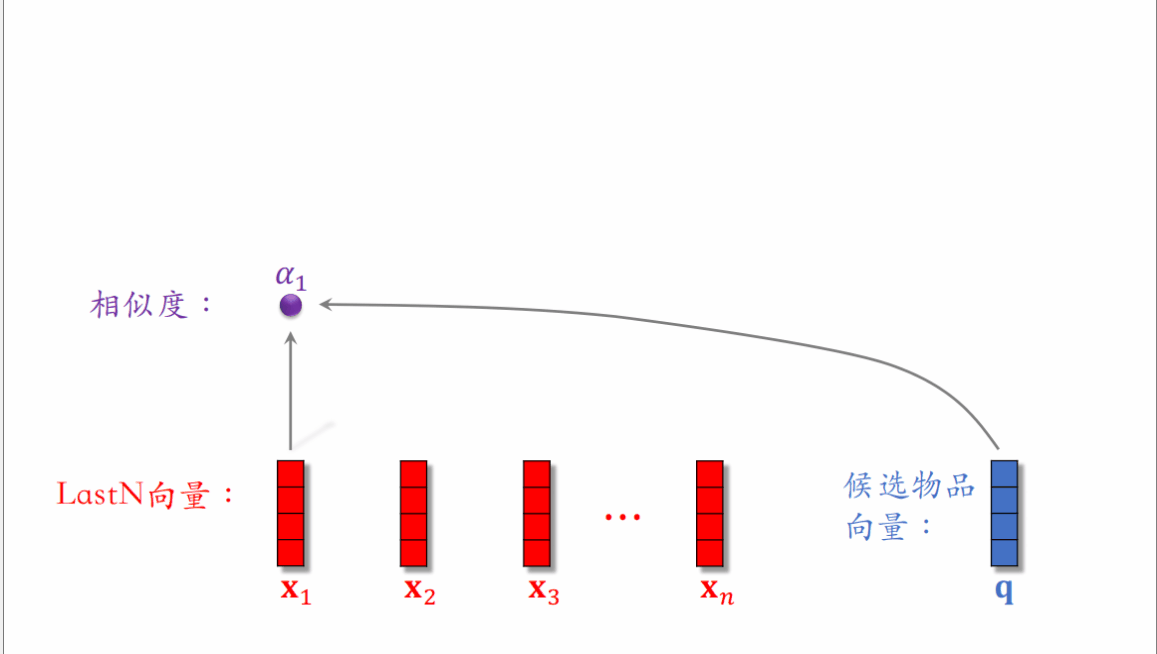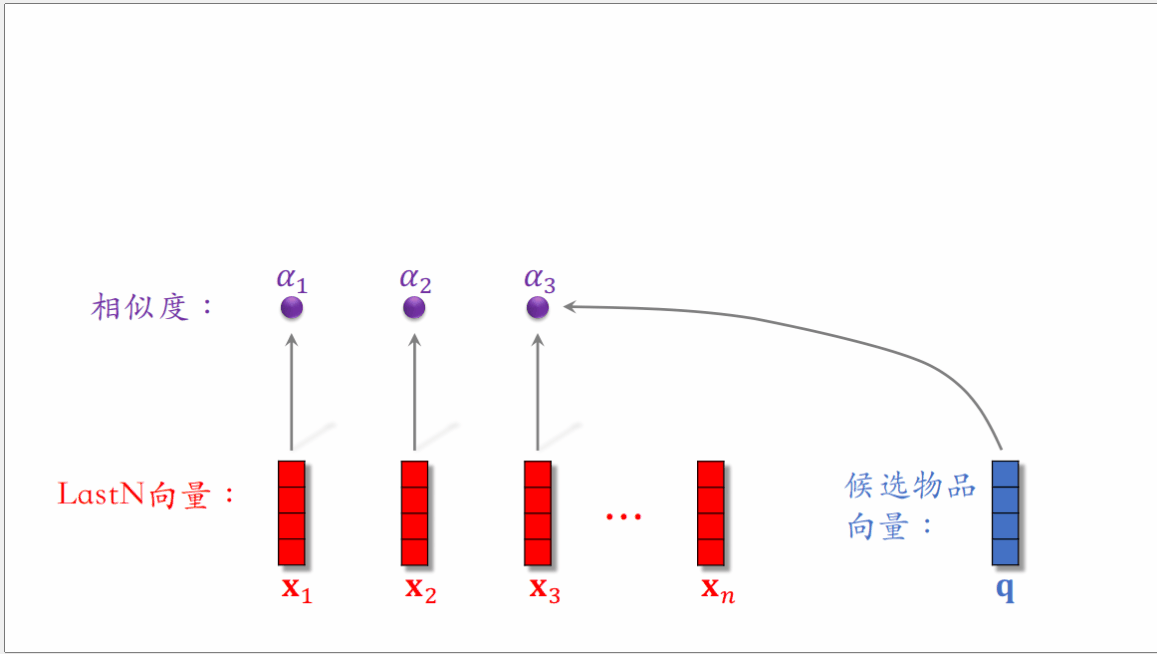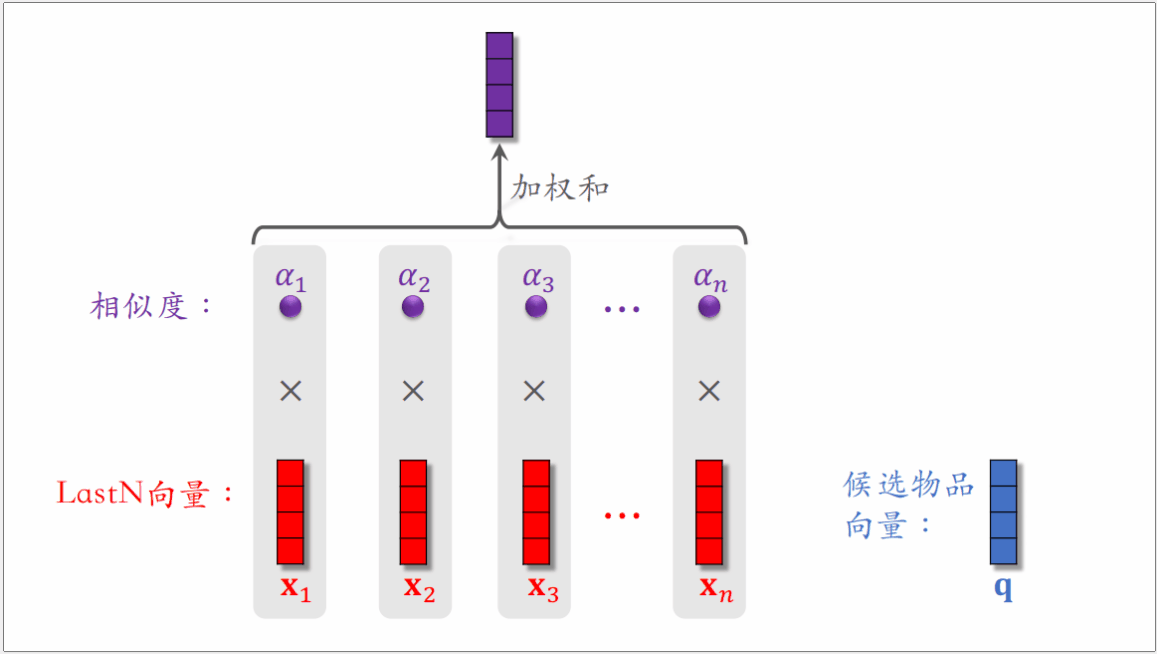
对于某候选物品,计算它与⽤户 LastN 物品的相似度,以相似度为权重,求⽤户 LastN 物品向量的加权和,把得到的向量作为⼀种⽤户特征(可以看作是对用户LastN历史记录的表征,反映用户的历史兴趣),输⼊排序模型,预估(⽤户,候选物品)的点击率、点赞率等指标。
DIN模型的本质是注意力机制,将LastN物品向量作为key和value,候选物品作为query。 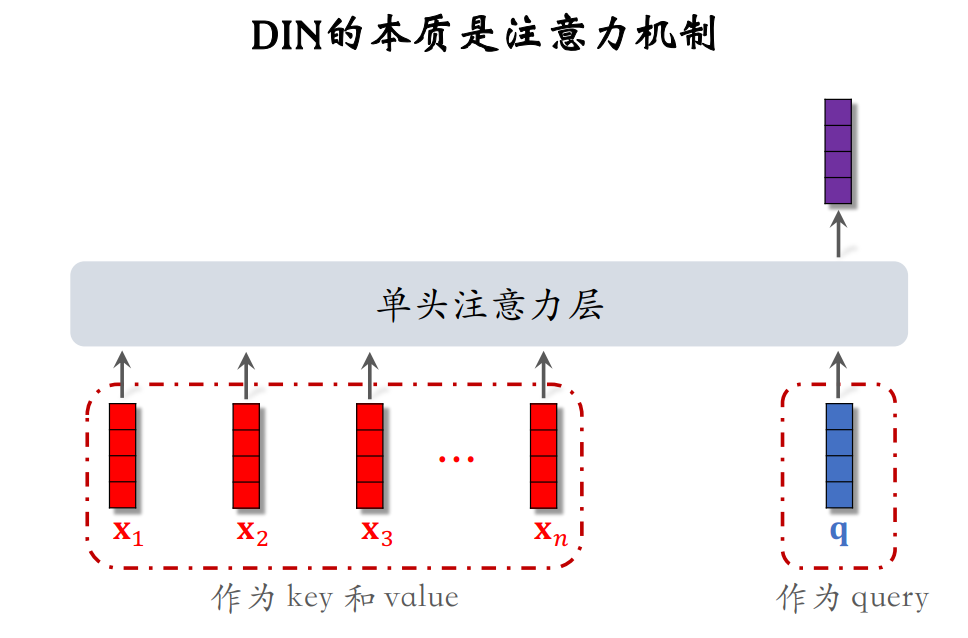
注意⼒机制不适⽤于双塔模型、三塔模型。因为注意⼒机制需要⽤到 LastN + 候选物品。而双塔、三塔模型中⽤户塔看不到候选物品,所以不能把注意⼒机制⽤在⽤户塔。
SIM模型
对于DIN模型来说,只能记录最近⼏百个物品,否则计算量太⼤。所以也就导致DIN模型只能关注短期兴趣,遗忘长期兴趣。
SIM模型是针对DIN模型进行的改进。我们观察到当LastN物品与候选物品差异很大时,二者相似度很低,权重就接近为0,此时这一个LastN物品的存在就可有可无了。所以据此,我们在注意力机制之前,可以先快速排除掉与候选物品无关的 LastN 物品,降低注意⼒层的计算量。
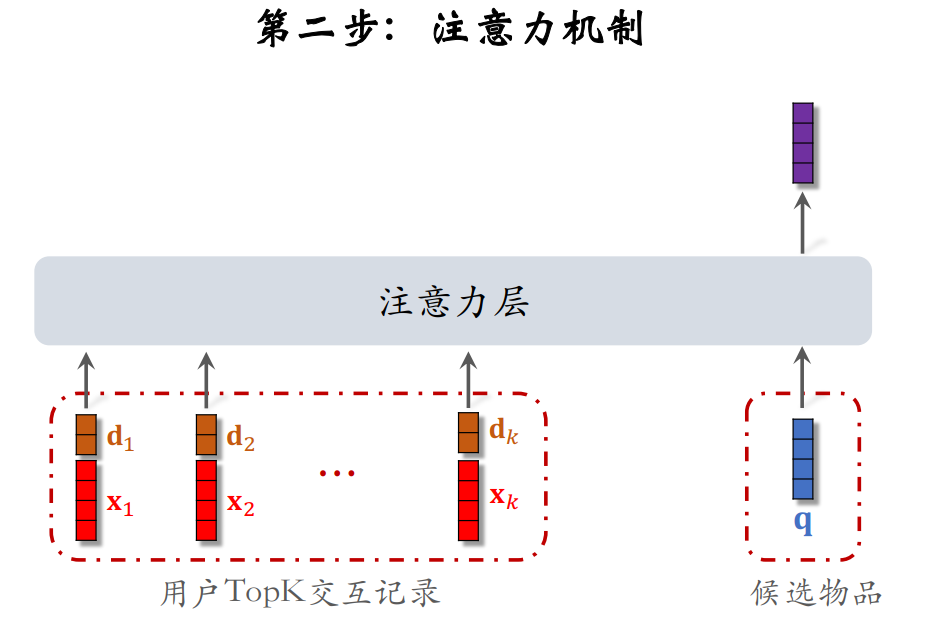
SIM模型可以令n的⼤⼩为⼏千,然后对于每个候选物品,在⽤户 LastN 记录中做快速查找,找到 k 个相似物品。把 LastN 变成 TopK,然后输⼊到注意⼒层。这样就可以保留用户的长期行为记录。
SIM 模型主要包括两个步骤。第一步:查找;第二步:注意力机制。
查找的方法主要有两种,Hard Search和Soft Search. 
注意力机制时,SIM模型还加入了时间信息,因为SIM序列很长,记录用户的长期序列,时间越久远,重要性越低。而DIN模型记录的都是最近几百个物品,都是近期行为,没必要加上时间信息。