搜广推学习之路(二)
深度学习
循环神经网络(RNN)
普通前馈神经网络(如CNN)一般处理的是固定长度、互不相关的输入,比如一张图片、一个固定长度的特征向量。但很多任务中,当前时刻的输出跟“之前发生了什么”强相关,例如:机器翻译:当前要翻译的词要看前面一句话的意思;语言模型:预测下一个词要看前面所有词;股票预测:今天的走势与过去几天的价格、成交量有关。因此,为了能够更好的处理序列的信息,RNN产生了。
首先介绍一下RNN的基础结构,如下图所示: 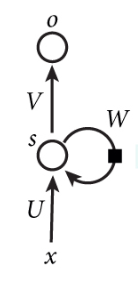
在解析这张图之前,我们先将W即其所在圆圈忽略,那么就是一个全连接神经网络的简略图,展开即下图所示: 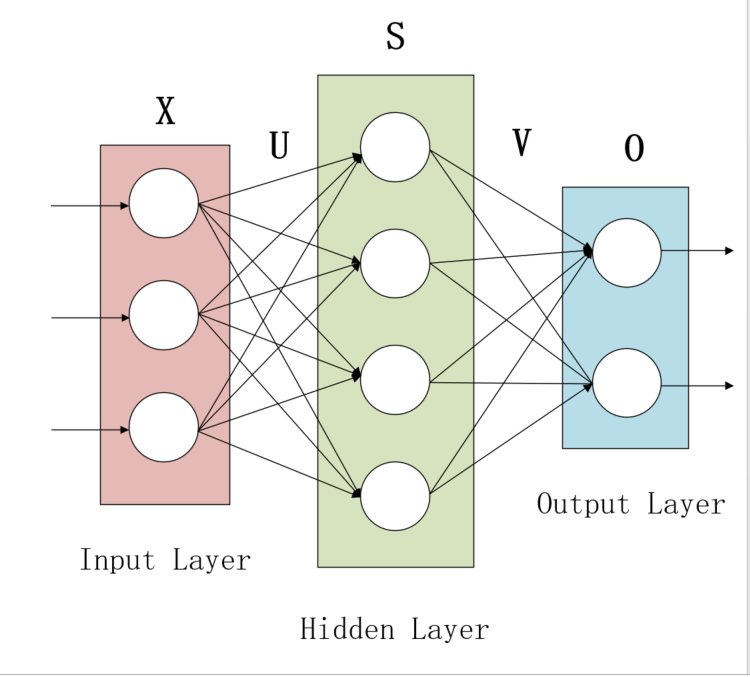
X是神经网络的输入向量,U是输入层到隐藏层的参数矩阵,S是隐藏层的输出向量,V是隐藏层到输出层的参数矩阵,O是输出层的向量,即为神经网络的输出向量。
那么RNN中的W是什么?这个W参数就是RNN实现“记忆”的关键。我们将RNN结构图展开如下图所示: 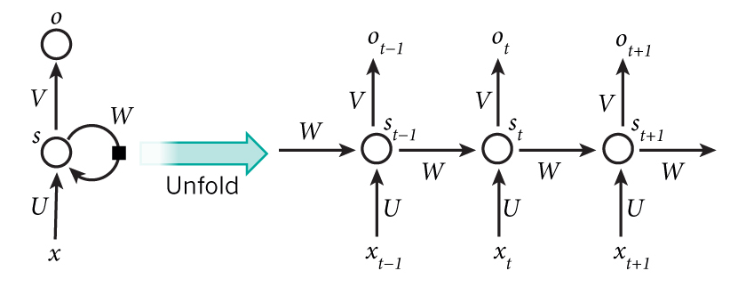
- xt表示网络每一时刻的输入
- ot表示网络每一时刻的输出
- st表示网络的隐藏层的状态输出
- U、V、W是RNN在所有时刻的共享参数
根据该展开图,我们可以得到RNN的计算公式: 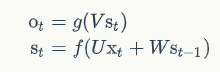
其中g( ⋅ )和f( ⋅ )函数均为激活函数。我们若将状态st不断使用公式进行展开就可以得到: 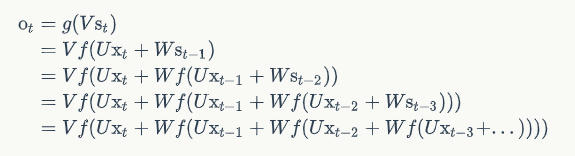
从上面可以看出,循环神经网络的输出值,是受前面历次输入值xt、xt − 1、xt − 3、...影响的,这就是为什么循环神经网络可以“记忆历史”。
为了方便与LSTM进行对比,在这里给出RNN的一个新的结构图,这里的ht即为我们上述提到的st,隐藏层状态。 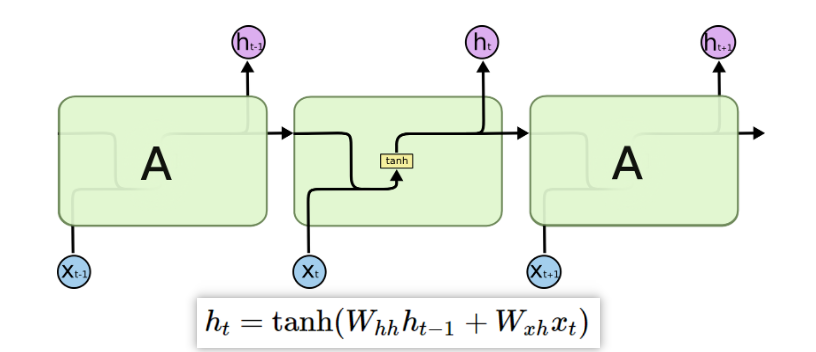
LSTM
对于普通RNN来说,当序列很长时,RNN很难将早期步骤的信息传递到后期步骤。比如,在句子“这只猫因为吃了太多的奶酪,所以现在……很饱”中,RNN可能早就忘记了主语是“猫”,导致后面预测错误。它更擅长记忆“短期”信息,而遗忘“长期”信息。而针对该问题,LSTM被提出。
LSTM主要由细胞状态和门控机制组成,而门控机制又由遗忘门、输入门和输出门组成。 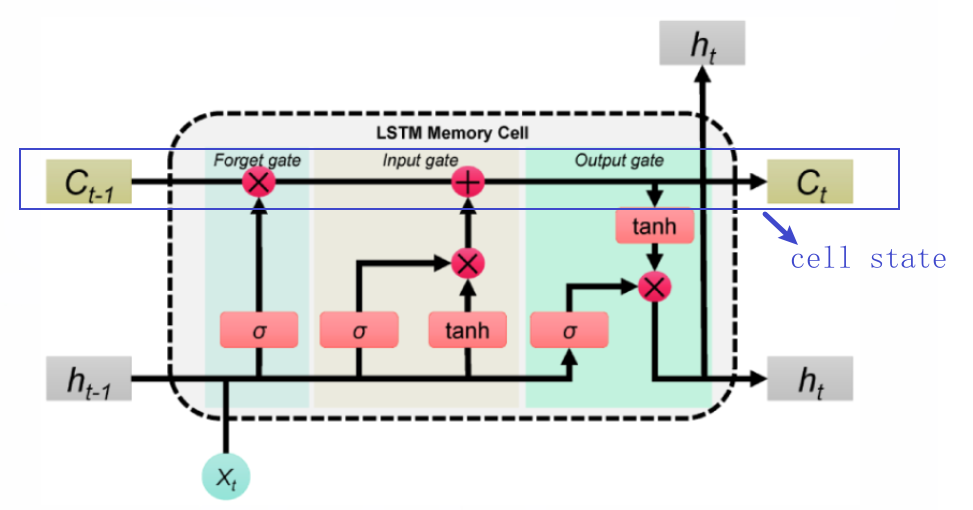
LSTM首先会决定从细胞状态中丢弃哪些信息。通过x和ht的操作,并经过sigmoid函数,得到0,1的向量,0代表清除记忆,1代表保留记忆. 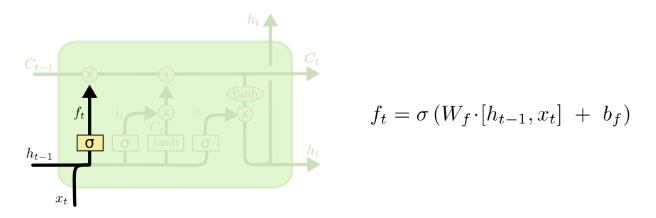
下一步决定将哪些新信息存储在细胞状态中。这分为两部分,首先,一个sigmoid层决定要更新哪些值。接下来,tanh层创建一个新的候选值向量,代表可能会加入到状态中的新内容。将把这两者结合起来,以更新状态。 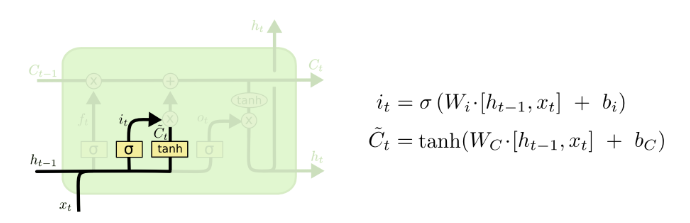
得到需要遗忘和新增的记忆后,我们就可以更新细胞状态。将旧状态与遗忘向量相乘,忘掉我们决定忘记的东西。然后加上新的候选值。 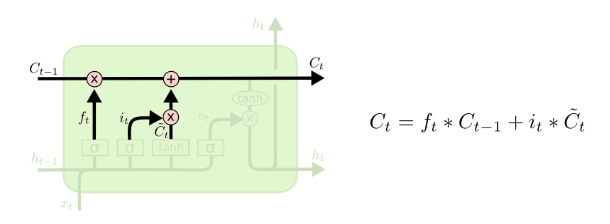
最后我们决定输出什么,这个输出也是新的隐藏层状态ht。首先,我们运行一个sigmoid层,它决定输出细胞状态的哪些部分。然后,我们将细胞状态输入到tanh层(为了将值压在−1和1之间)并将其乘以sigmoid门的输出,这样我们就只输出我们决定要输出的部分。 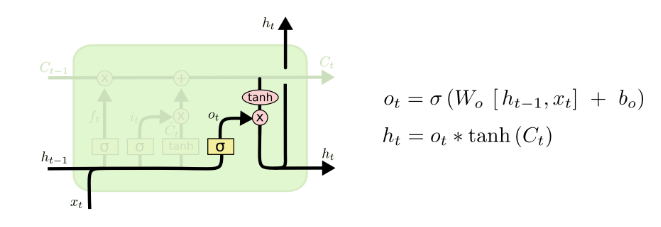
自注意力机制
自注意力(Self-Attention)机制是一种特殊的注意力机制,对于序列中的每一个元素(比如一个词),它会计算序列中所有其他元素对该元素的“重要性”或“相关度”,从而帮助模型更好地理解序列中的上下文信息,更准确地处理序列数据。
比如在处理“这只动物没有穿过街道,因为它太累了。”这个句子时,模型通过计算句子中所有其他词与 “它” 的相关性,可以判断 “动物” 与 “它” 的联系最紧密,所以得到“它”指的是“动物”而不是“街道”。
为了实现上述思想,自注意力机制引入了三个重要的向量:查询(query)、键(key)和值(value)。
接下来具体阐述自注意力机制的过程,下图所示公式即为自注意力机制的核心: 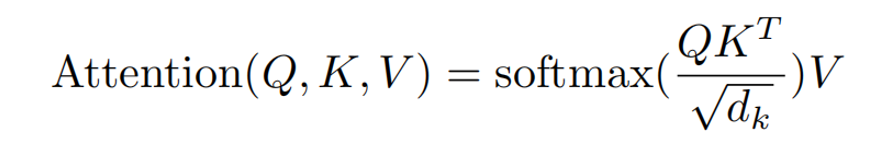
自注意力机制公示的本质可以看作是softmax(XXT)X,下面给出一个具体的例子,来探究该公式的具体意义。
首先是XXT,根据定义,两个向量的点积是两个向量的长度与它们夹角余弦的积。如果两向量夹角为90°,那么结果为0,代表两个向量线性无关。如果两个向量夹角越小,两向量在方向上相关性也越强,结果也越大。点积反映了两个向量在方向上的相关性,结果越大越相关。然后使用一个Softmax函数,对其归一化,可以凸显相关性最大的值并抑制远低于最大值的其他分量。最后使用softmax(XXT)点乘X,就可以将得到的相关性信息也包含到X向量中。
注意下图中的数字是我随便编的,只起到一个帮助理解的作用,不对具体意义负责。 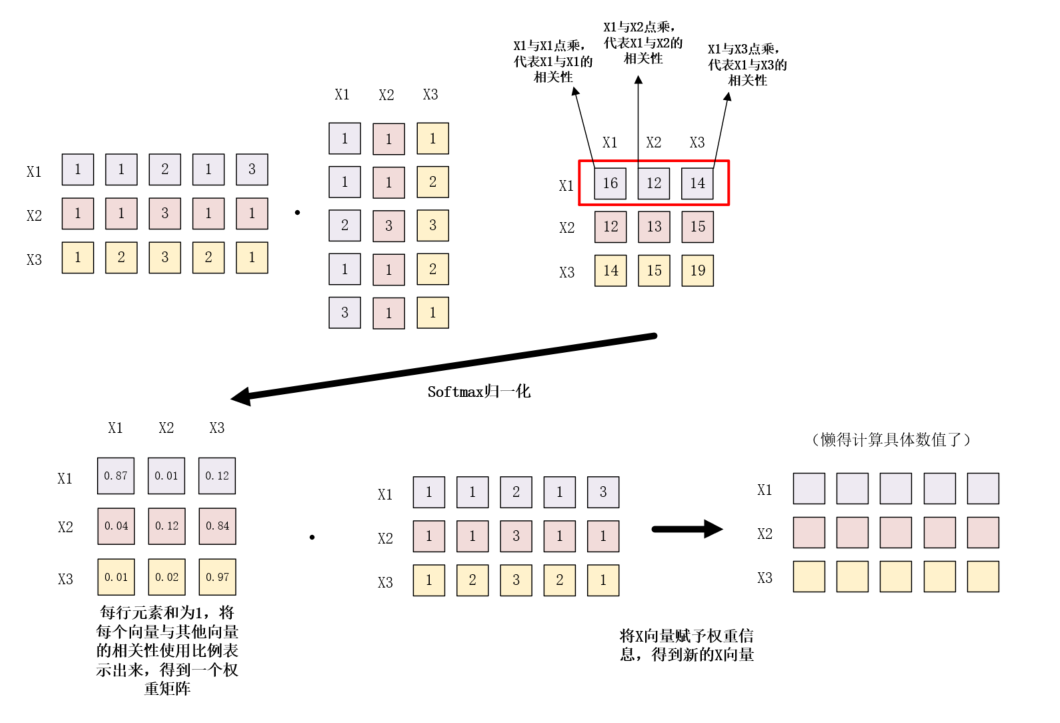
对自注意力机制的本质了解后,自注意力机制本身的公式也很好理解了,将X与矩阵Wq、Wk、Wv相乘,得到Q、K、V向量后执行相同的操作。(矩阵Wq、Wk、Wv是训练得到的)
那么问题来了,我们为什么不能直接使用X,而要再引入Q、K、V?自注意力机制为了让每个 token 既能“提问”、又能“被识别”、还要“贡献内容”,必须把输入 X 映射成 3 个角色:Q、K、V。三个线性变换让模型在不同子空间中学习匹配模式和信息提取,极大增强了表达能力。同时线性变换引入了额外的可学习参数Wq、Wk、Wv。这增加了模型的容量,使其能够拟合更复杂的数据分布和语言现象。
“提问”:这是query的角色。序列中的每个token都通过Q向量发出一个query:在这个上下文中,哪些token的信息对我最重要?
“被识别”:这是key的角色。每个token都通过K向量提供一个“身份标识”,用于回应其他token的查询,告诉别人“我是谁,我有什么特征”。
“贡献内容”:这是value的角色。每个token都通过V向量来提供它最终要贡献的“实质信息内容”。这个信息可能需要是经过提炼的,与原始输入不同。
除了上述问题,在注意力机制中还除以了根号dk,是为了防止点积 QKT 随维度增大而数值过大,使 Softmax 的梯度过小,从而导致训练不稳定。本质是对点积进行标准化,使其在 Softmax 中保持适当的数值范围,避免梯度消失,稳定训练。下图给出一个具体的例子: 
至此,自注意力机制就解释清楚了,我们最后给出自注意力机制的完整图解。 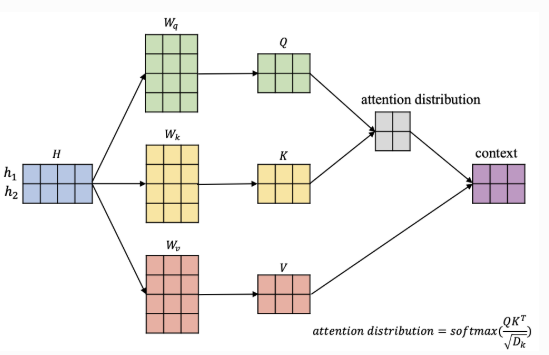
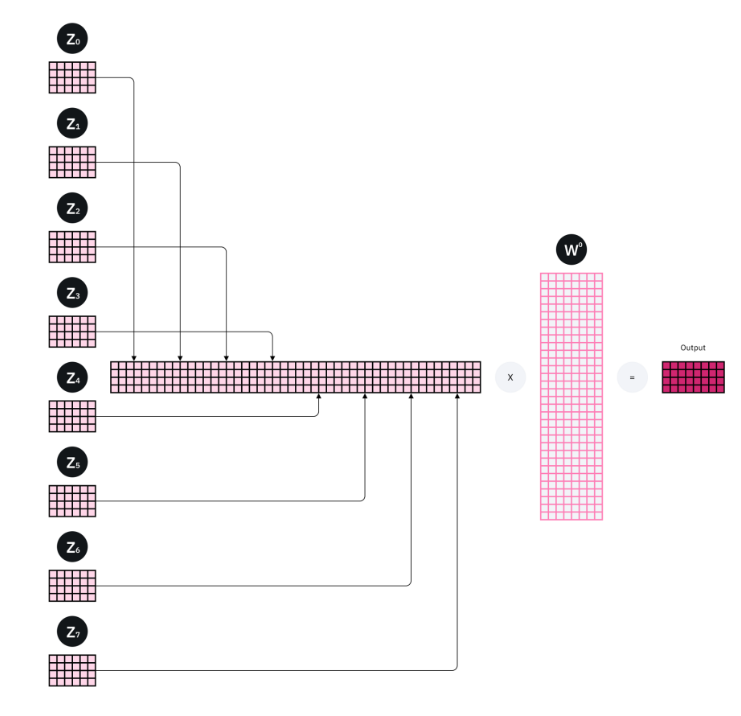
多头注意力机制是将多个自注意力机制组合形成的,在transformer中使用了8个多头注意力机制,所以我们这里也以8个自注意力机制为例。多头注意力机制首先使用8个w矩阵生成Q、K、V,执行8次自注意力机制得到8个Z矩阵,然后将8个Z矩阵拼接起来(Concat),然后乘附加权重矩阵Wo得到最终的Z。 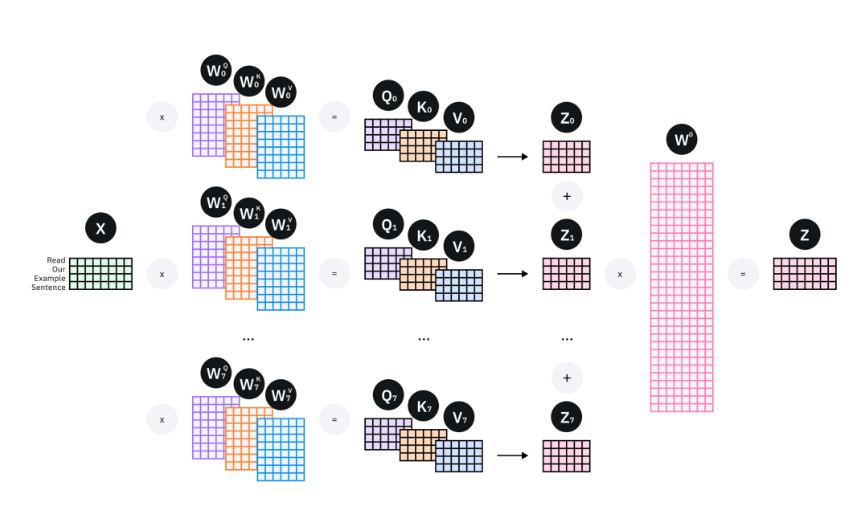
Transformer
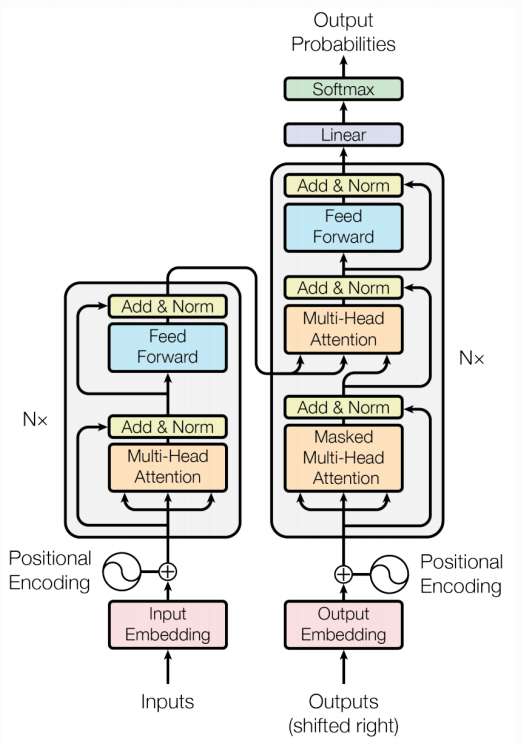
transformer的结构可分为encoder和decoder两大部分,其中encoder部分有6个encoder块,decoder部分也有6个decoder块。encoder部分最后一个encoder块的信息会传递给每一个decoder块使用。 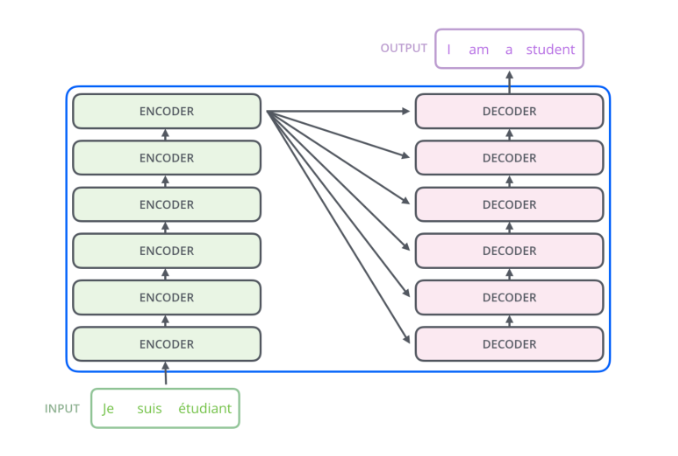
在介绍具体架构前,我们先介绍输入部分,由于transformer是并行处理数据的,所以transformer并不像RNN一样,可以包含时间顺序,为了解决这一问题,transformer在输入部分添加了位置编码 Positional Encoding。下图为位置编码公式: 
为了理解上述表达式,我们以dmodel = 4的短语“I am a robot”为例,展示该短语的位置编码矩阵,为了方便计算,我们使用100代替公式中的10000。需要说明的是i的计算,短语维度为4,2i表示偶数维度,2i+1表示奇数维度,所以对于四个维度0、1、2、3,对应的i为0、0、1、1。 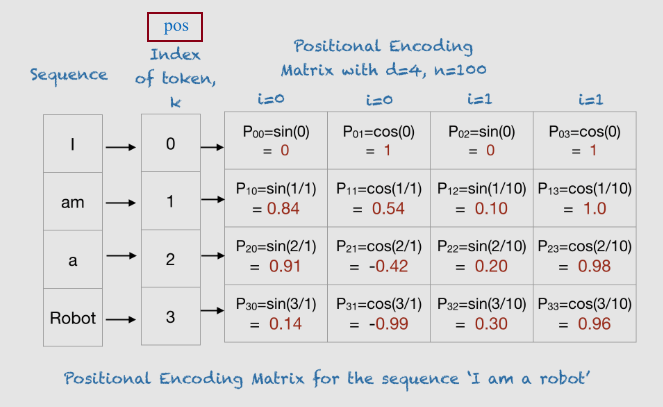
有了位置编码后,我们将输入向量x与其对应的位置编码相加就可以得到transformer的输入。 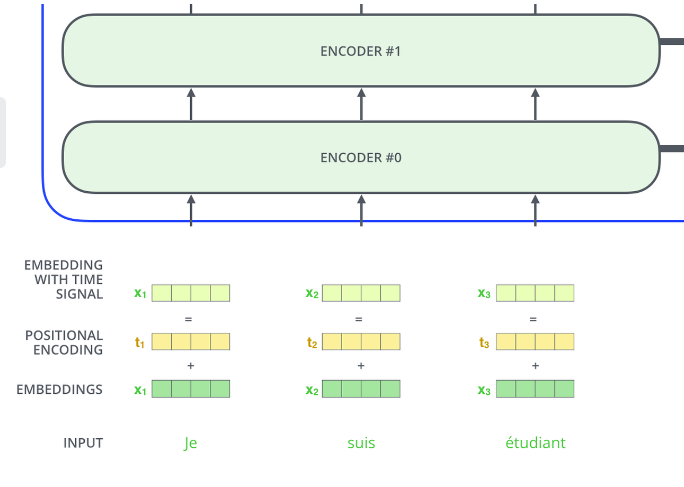
然后我们介绍encoder部分,该部分由 Multi-Head Attention, Add & Normalize, Feed Forward, Add & Normalize 组成的。 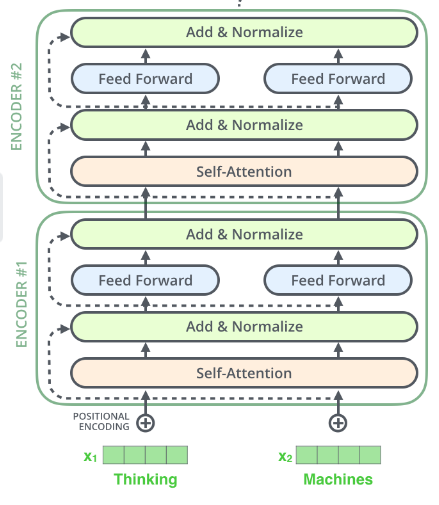
Add & Normalize层包括Add和Normalize两部分,这里的Add是残差连接,即y = x + F(x)。在encoder中即为X + SelfAttention(X)和X + FeedForward(X)。 
残差连接之后,将结果normalize,normalize 指 Layer Normalization,通常用于 RNN 结构,Layer Normalization 会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
Feed Forward就是一个两层的神经网络,先线性变换,然后ReLU非线性,再线性变换。
encoder部分就结束了,接下来我们介绍decoder部分。 首先是decoder部分的输入,在训练阶段,我们采用teacher forcing策略,假设我们的训练数据为“I love you”,而经翻译得到的目标序列为“我爱你”,那么我们将目标序列加上特殊符号, < Begin>表示序列开始, < end>表示序列结束,这样完整的目标序列就为“ < Begin>我爱你 < end>”,而decoder的输入需要将完整的目标序列右移一位,并去掉结尾的 < end>,所以decoder的输入就为“ < Begin>我爱你”。
decoder部分与encoder部分不同的有两个地方,decoder部分包含有两个 Multi-Head Attention 层,其中第一个 Multi-Head Attention 层采用了 Masked 操作;第二个 Multi-Head Attention 层的K,V矩阵使用 Encoder 的编码信息矩阵(最终输出)进行计算,而Q使用 Decoder 第一个自注意力输出计算,所以第二个注意力机制也被叫做Cross-Attention 交叉注意力。
接下来我们具体介绍 Masked Multi-Head Attention层。如果没有 Mask,在训练时,Decoder 在计算第一个词 < Begin> 的表示时,就能“看到”整个答案序列(如“我爱你”)。这被称为信息泄露。模型会学会简单地复制输入中的下一个词,而不是真正学习如何基于上文进行预测。所以为了确保生成目标,我们在注意力机制中引入一个掩码(Mask),来屏蔽掉未来的信息。下图为具体的过程,之后的softmax、与V相乘等过程与一般的多头注意力机制一致,所以没有给出。 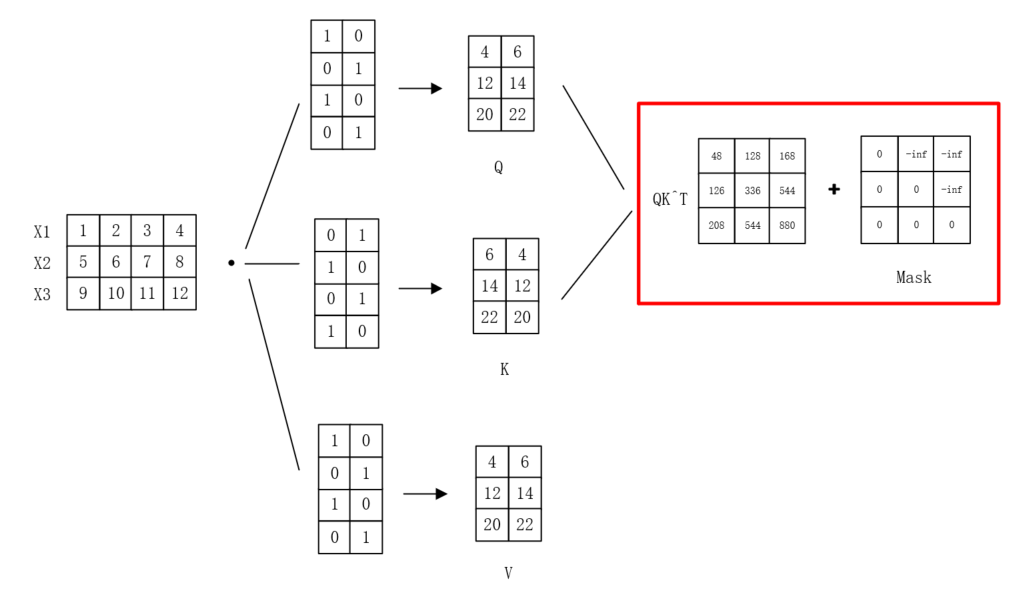
而交叉注意力机制很简单,只要将encoder最后一层的K和V矩阵用于每一层的decoder即可,其余部分与一般的多头注意力机制没有区别。 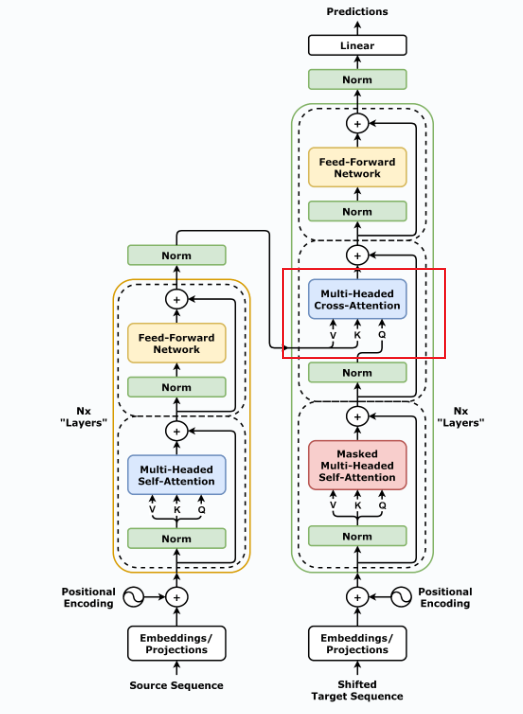
至此,transformer就介绍完了。